빅데이터 분석
7. 빅데이터 분석
-
빅데이터 분석 개요
-
빅데이터 분석에 활용되는 기술
-
분석 파일럿 실행 1단계 - 분석 아키텍처
-
분석 파일럿 실행 2단계 - 분석 환경 구성
-
분석 파일럿 실행 3단계 - 임팔라를 이용한 데이터 실시간 분석
-
분석 파일럿 실행 4단계 - 제플린을 이용한 실시간 분석
-
분석 파일럿 실행 5단계 - 머하웃을 이용한 데이터 마이닝
-
분석 파일럿 실행 6단계 - 스쿱을 이용한 분석 결과 외부 제공
빅데이터 분석 개요
-
탐색 단계 : 데이터를 관찰하고 이해하는 과정
-
분석 단계 : 탐색과 분석을 반복하며 의미 있는 데이터를 추출해 문제를 명확히 정의하고 해결하는 과정
-
강력한 오픈소스 기술을 기반으로 수평적 확장이 가능해 저비용으로 선형적인 분석 성능 보장
-
내부업무 시스템에서 발생했던 수년치 데이터를 외부 데이터와 쉽게 결합 가능
분석의 유형
기술 분석
-
분석 초기 데이터의 특징을 파악하기 위해 선택, 집계, 요약등의 양적 기술 분석 수행
-
평균, 분산, 표준편차
탐색 분석
-
업무 도메인 지식을 기반으로 대규모 데이터셋의 상관관계나 연관성을 파악
추론 분석
-
전통적인 통계분석 기법으로 문제에 대한 가설을 세우고 샘플링을 통해 가설을 검증
인과 분석
-
문제 해결을 위한 원인과 결과 변수를 도출하고 변수의 영향도 분석
예측 분석
-
대규모 과거 데이터를 학습해 예측 모형을 만들고, 최근의 데이터로 미래를 예측
빅데이터의 가치 P301 그림 7-2 빅데이터 분석 프로세스
-
Raw 데이터 => 정보(Information) => 통찰력(Insight) => 가치(Value)
-
통찰력을 갖게 되는 단계에서 빅데이터 활용 효익 발생
-
상품 및 서비스 개발, 마케팅 및 캠페인 지원, 리스크 관리 영역등의 주요 의사결정에 빅데이터 이용
-
새로운 분석 주제와 가설들을 풍부하게 하고 신뢰도 높은 분석 결과를 도출 가능
-
스마트카 빅데이터 분석에 SNS, 포털, 날씨, 뉴스, 위치 정보 등과 결합되면 차별화된 타겟 마케팅 가능
-
포털과 블로그등의 게시판을 크롤링해서 자사/타사 브랜드 평판과 트랜드 분석으로 신제품 개발과 프로모션등에 활용
-
-
스마트카의 상태 및 운행 이력 데이터와 외부의 날씨, 도로지형, 교통상황을 결합해 분석
-
스마트카의 고장 및 결함에 대한 패턴과 원인을 찾아서 안전한 스마트카 서비스가 가능 해짐
-
빅데이터 분석에 활용할 기술
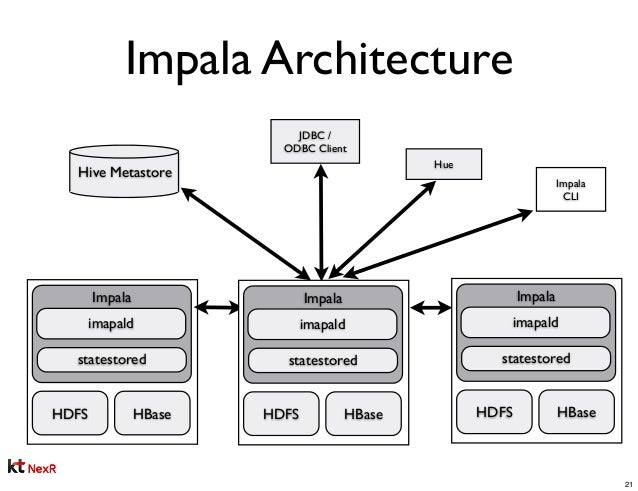
임팔라(Impala)
-
하이브 : SQL On Hadoop 으로 MapReduce 대체, 배치성 분석
-
임팔라 : 실시간 빅데이터 분석 질의가 가능
-
구글 논문 드레멜(Dremel) -> 클라우데라 임팔라(Impala) 개발
-
Impalad : 하둡의 데이터노드에 설치되어 임팔라의 실행 쿼리에 대한 계획, 스케줄링, 엔진을 관리하는 코어 영역
-
Query Planner: 임팔라 쿼리에 대한 실행 계획 수립
-
Query Coordinator: 임팔라 잡리스트 및 스케줄링 관리
-
Query Exec Engine: 임팔라 쿼리를 최적화해서 실행, 결과 제공
-
Statesored: 분산 환경에 설치돼 있는 Impalad의 설정 정보 및 서비스 관리
-
Catalogd: 임팔라에서 실행된 작업 이력 관리 및 제공
임팔라 아키텍처
활용 방안
-
하이브 쿼리를 임팔라 쿼리로 변경
-
스마트카 데이터셋을 실시간 탐색과
-
하이브 쿼리 대부분 임팔라 쿼리와 호환
-
하이브 대비 빠른 응답 속도 보장
제플린(Zeppelin)
-
데이터를 효과적으로 탐색 및 분석하기 위한 분석 및 시간화 툴 => R
-
R => Hadoop 직접 참조하거나 분산 병렬처리가 어려움
-
RHive, RHadoop, RHipe 같은 도구로 HDFS 병렬 처리 가능
-
복잡도가 높아지고 안정적인 사용을 위해서 추가 비용 발생
-
-
스파크를 기반으로 한 제플린 탄생
-
국내 스타트 기업 NFLabp에서 주도
-
NoteBook : 웹상에서 제플린의 인터프리터 언어를 작성하고 명령 실행 및 관리 UI
-
Visualization: 인터프리터 실행 결과를 곧바로 웹상에서 다양한 시각화 도구로 분석해 볼 수 있는 기능
-
Zeppelin Interpreter: 데이터 분석을 위한 다양한 인터프리터를 제공
-
스파크, 하이브, JDBC, 쉘등 필요시 인터프리터 추가 확장
활용 방안
-
5개의 마트 데이터를 대상으로 제플린에서 스파크 SQL을 이용해 다양한 Ad-hoc 분석 수행
-
그 결과를 제플린 시각화 기능을 이용해 다양하게 분석
머하웃(Mahout)
-
Hadoop 생태계에서 머신러닝 기법을 이용해 데이터 마이닝을 수행하는 툴
-
Hadoop 분산 아키텍처를 바탕으로 텍스트 마이닝, 군집, 분류등과 같은 머신러닝 기반 기술 내재화
-
추천(Recommendation): 사용자들이 관심을 가졌던 정보나 구매했던 물건의 정보를 분석해서 추천하는 기능
-
사용자 기반 추천: 유사한 사용자를 찾아 추천
-
아이템 기반 추천: 항목 간 유사성을 계산해서 추천 항목 생성
-
-
분류(Classification): 데이터셋의 다양한 패턴과 특징을 발견해 레이블을 지정하고 분류하는 기능
-
주요알고리즘: 나이브 베이지안, 랜덤 포레스트, Canopy등 지원
-
-
군집(Clustering): 대규모 데이터셋에서 새로운 특성으로 데이터의 군집들을 발견하는 기능
-
주요알고리즘: K-Means, Fuzzy, C-Means, Canopy등
-
-
감독학습(Supervised Learning): 학습을 위한 데이터셋을 입력해서 분석 모델을 학습시키는 머신러닝 기법
-
학습된 분석 모델을 이용해 예측하고 최적화
-
분류와 회귀 분석 기법
-
-
비감독학습(Unsupervised Learning): 학습 데이터셋을 제공하지 않고 데이터의 특징적인 패턴을 발견하는 머신러닝 기법
-
사람이 구분 및 그루핑하기 어려운 현상들을 자동으로 그루핑 하는데 사용
-
군집 기법
-
활용 방안
-
스마트카 Managed 영역에 적재된 "스마트카 상태 데이터"와 "운전자 운행 데이터"를 이용해 감독학습-분류, 비감독학습-군집 머신러닝 수행
-
추천 기능을 활용해 "차량용품 구매 이력 데이터"를 분석
-
스마트카 운전자 가운데 유사 그룹 간의 구매 선호도에 따라 차량용품 추천 작업
-
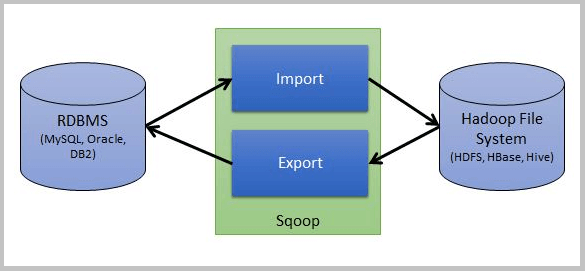
스쿱(Sqoop)
-
RDBMS <=> 적재(import, export) <=> HDFS
-
Sqoop Client, Sqoop Server
-
Connector: 다양한 DBMS 접속 어댑터 및 라이브러리
스쿱 아키텍처
활용 방안
-
하이브, 임팔라, 제플린, 머하웃등에서 분석한 결과를 외부 RDBMS로 Export 용도로 사용
-
참고: 스쿱은 하둡 생태계에서 수집(Import) 기술로 분류
분석 파일럿 실행 1단계 - 분석 아키텍처
분석 요구사항
요구사항 - 빅데이터 탐색을 통해 해결
-
요구사항 1 : 차량의 다양한 장치로부터 발생하는 로그 파일을 수집해서 기능별 상태 점검
-
요구사항 2: 운전자의 운행 정보가 담긴 로그를 실시간으로 수집해서 주행 패턴을 분석
요구사항 확장
-
빅데이터 실시간 탐색 및 시각화
-
머신러닝을 이용한 데이터 마이닝
요구사항 구체화 및 분석
스마트카 데이터셋을 좀 더 빠르게 탐색 및 분석
-
임팔라 이용 하이브 배치 쿼리를 온라인 쿼리로 실행
스마트카 데이터셋의 탐색 결과를 이해하기 쉽게 시각화
-
스파크 SQL로 탐색 후 결과를 제플린의 차트로 시각화
차량용품 구매 이력을 분석해 최적의 상품 추천 목록 만들기
-
머하웃의 추천 기능 이용, 성향에 따른 상품 추천 목록 생성
스마트카 상태 정보를 분석 이상 징후 예측
-
머하웃의 분류 감독 학습을 통해 이상 징후에 대한 예측 모델 구성
스마트카 운행 정보를 분석 운행 패턴별 군집을 도출
-
머하웃의 군집 비감독 학습을 통해 운행 패턴에 대한 군집을 도출
분석된 결과를 외부 업무 시스템의 RDBMS로 제공
-
스쿱의 데이터 익스포트 이용, HDFS => RDBMS
분석 아키텍처
휴 - Impala Editor
-
임팔라 설치하면 휴 > Editor 메뉴에 Impala Editor 추가됨
-
스마트카 상태 정보 On-Line 조회
-
운전자 운행 정보 On-Line 조회
제플린 - NoteBook
-
웹 브라우저에 Spark-SQL로 데이터셋 분석
-
제플린에서 제공하는 다양한 차트로 시각화
머하웃 - 추천 라이브러리
-
추천 라이브러리에 "차량용품 구매 정보" 데이터셋 지정
-
상품 평가 정보에 대한 운전자 취향을 분석해 취향이 비슷한 운전자에게 구매 가능성이 높은 상품 추천
머하웃 - 분류 라이브러리
-
분류 라이브러리로 "스마트카 이상 징후"를 예측하기 위한 모델 생성
-
트레이닝 데이터로 "스마트카 상태 정보" 데이터셋 이용
-
알고리즘: 랜덤 포레스트 선택
-
최종적으로 트레이닝된 분류모델(Classify)를 애플리케이션에 적용
머하웃 - 군집 라이브러리
-
군집 라이브러리를 이용 "스마트카 운전자의 운행" 데이터셋에 대해 K개의 군집으로 형성되는 K-means 적용
-
탐색 단계에서는 식별되지 않은 새로운 운행 패턴 발견 및 분석
-
스쿱 - 분석 결과 Export
-
스쿱의 CLI 명령 중 Export 기능으로 HDFS에 저장된 분석 결과를 RDBMS(PostgreSQL)에 제공
분석 파일럿 실행 2단계 - 분석 환경 구성
-
CM을 이용해 임팔라, 스쿱 설치
-
제플린 직접 설치
임팔라 설치
-
Cluster1 > 선택 메뉴 > 서비스 추가
-
Impala 선택 > ICS, ISS, ID > Server03
-
변경 내용 검토 > 기본값 선택 후 계속
임팔라 설치후
-
Cluster1 > Hue > [구성] > 검색 > Impala > 선택
-
Cluster1 > Impala > 시작
-
Cluster1 > Hue > 재시작
-
Hue > Web UI > Query Editor > Impala 추가 확인
스쿱 설치
-
Cluster1 > 선택 메뉴 > 서비스 추가
-
Sqoop 1 Client 선택 > G > 호스트 선택 > Server03
-
변경 내용 검토 > 기본값 선택 후 계속
스쿱 설치 후
- 스쿱은 클라이언트로 서버 기동 없음
제플린 설치
Download
-
Server02 sshd
-
cd /home/pilot-pjt/
-
wget https://archive.apache.org/dist/zeppelin/zeppelin-0.6.2/zeppelin-0.6.2-bin-all.tgz
압축 해제
-
tar -xvf zeppelin-0.6.2-bin-all.tgz
환경 설정
-
cd /home/pilot-pjt/zeppelin-0.6.2-bin-all/conf
-
cp zeppelin-env.sh.template zeppelin-env.sh
-
vi zeppelin-env.sh
export JAVA_HOME=/usr/java/??
export HADOOP_CONF_DIR=/etc/hadoop/conf-
chmod 777 /tmp/hive
제플린에서 하이브 인터프리터 사용을 위해 설정 복사
-
cp /etc/hive/conf/hive-site.xml /home/pilot-pjt/zeppelin-0.6.2-bin-all/conf
서비스 포트 변경 : 8080 => 8081
-
스파크 마스터 서비스: 8080
-
cd /home/pilot-pjt/zeppelin-0.6.2-bin-all/conf
-
cp zeppelin-site.xml.template zeppelin-site.xml
-
vi zeppelin-site.xml
-
:/8080
<property>
<name>zeppelin.server.prot</name>
#<value>8080</value>
<value>8081</value>
...
<property>root 계정에 path 설정
-
vi /root/.bash_profile
-
PATH=$PATH:/home/pilot-pjt/zeppelin-0.6.2-bin-all/bin
-
source /root/.bash_profile
서비스 시작 및 확인
-
zeppelin-daemon.sh start
-
안되면 8080으로 접속
머하웃 설치
-
클라우데라 하둡 배포판에 이미 설치되어 있음
-
머하웃 명령을 실행할 Sever02의 환경변수에 하둡 클라이언트 옵션(HADOOP_CLIENT_OPTS) 힙 메모리 설정
-
vi /etc/profile
-
맨 마지막 줄 : export HADOOP_CLIENT_OPTS="-Xmx1024m"
-
source /etc/profile
머하웃 설치 확인
-
mahout -help
-
Running on hadoop 확인
-
java.lang.ClassNotFoundException: -help 경고 메세지 무시
분석 파일럿 실행 3단계 - 임팔라를 이용한 실시간 분석
하이브 QL을 임팔라에서 실행 하기
하이브 QL
-
Hue > Query Editor > Hive
-
이상 운전 패턴 스마트카 정보 조회
-
select * from managed_smartcar_symptom_info where biz_date='20190101'
임팔라 QL
-
Hue > Query Editor > Impala
-
데이터베이스(default) 안보이면 새로고침 또는 임팔라 재시작
** 이상 운전 패턴 스마트카 정보 조회 **
select * from managed_smartcar_symptom_info where biz_date='20190101'** 긴급 점검이 필요한 스마트카 정보 조회 **
select * from managed_smartcar_emergency_check_info where biz_date='20190101'** 스마트카 차량용품 구매 이력 정보 조회 **
select * from managed_smartcar_item_buylist_info where biz_month='201901'임팔라를 이용한 운행 지역 분석
-
스마트카 운행 지역별 평균 속도가 가장 높았던 스마트카 차량 출력
-
결과 차트로도 확인
-
/CH07/ImpalaSQL/2nd/그림-7.35.sql
select
T2.area_number, T2.car_number, T2.speed_avg
from (
select
T1.area_number,
T1.car_number,
T1.speed_avg,
rank() over(partition by T1.area_number order by T1.speed_avg desc) as ranking
from (
select area_number, car_number, avg(cast(speed as int)) as speed_avg
from managed_smartcar_drive_info
group by area_number, car_number
) T1
) T2
where ranking = 1분석 파일럿 실행 4단계 - 제플린을 이용한 실시간 분석
제플린을 이용한 운행 지역 분석
스마트카가 운행한 지역들의 평균 속도가 높은 순으로 출력
-
접속안되면
-
cd /home/pilot-pjt/zeppelin-0.6.2.bin-all/bin
-
./zeppelin-daemon.sh start
-
./zeppelin-daemon.sh status
-
재플린 > NoteBook > Create new note > SmartCar-Project
-
스마트카 운전자 운행 파일 확인
-
%md => %sh
-
hdfs dfs -cat /user/hive/warehouse/managed_smartcar_drive_info/biz_date=20190101/* | head
-
노트북의 인터프리터를 스파크로 바인딩, 스칼라 코드 작성
-
%spark
-
/CH07/SparkSQL/2nd/그림-7.43.sql
// HDFS에서 데이터 로드
val driveData = sc.textFile("hdfs://server01.hadoop.com:8020/user/hive/warehouse/managed_smartcar_drive_info/biz_date=20160626/*")
// 로드한 데이터셋을 스파크에서 테이블 데이터 타입
case class DriveInfo(car_num: String, sex: String, age: String, marriage: String,
region: String, job: String, car_capacity: String, car_year: String,
car_model: String, speed_pedal: String, break_pedal: String, steer_angle: String,
direct_light: String, speed: String, area_num: String, date: String)
// 로드한 데이터셋을 스파크에서 데이터 구조로 변경
val drive = driveData.map(sd=>sd.split(",")).map(
sd=>DriveInfo(sd(0).toString, sd(1).toString, sd(2).toString, sd(3).toString,
sd(4).toString, sd(5).toString, sd(6).toString, sd(7).toString,
sd(8).toString, sd(9).toString, sd(10).toString,sd(11).toString,
sd(12).toString,sd(13).toString,sd(14).toString,sd(15).toString
)
)
// 스파크-SQL로 분석하기 위한 임시 테이블 생성
drive.toDF().registerTempTable("DriveInfo")-
참고: 스칼라
-
인터프리터 스파크-SQL로 변경
-
%spark.sql
select T1.area_num, T1.avg_speed
from (select area_num, avg(speed) as avg_speed
from DriveInfo
group by area_num
) T1
order by T1.avg_speed desc-
테이블 형식의 결과 확인
-
다양한 차트로 결과 확인
동적 변수를 추가해서 실행 해보기
select T1.area_num, T1.avg_speed
from (select area_num, avg(speed) as avg_speed
from DriveInfo
group by area_num having avg_speed >= ${AvgSpeed=60}
) T1
order by T1.avg_speed desc
제플린 스케줄러 기능으로 자동 실행 설정
-
상단 시계모양 ICON > Crom 표현이나 Preset 으로 시간 지정
-
1분 지정하고 자동 실행 출력 확인
제플린 인터프리터
-
다양한 인터프리터 제공하는
-
spark, pyspark, spark.sql, spark.mahout, spark.r 등등
분석 파일럿 실행 5단계 - 머하웃을 이용한 데이터 마이닝
-
사람이 인지하기 어려운 패턴 찾기
머하웃 추천 - 스마트카 차량용품 추천
사용 데이터셋
-
"스마트카 차량용품 구매 이력" managed_smartcar_item_buylist_info 10만건
추천에 필요한 항목
-
차량고유번호 car_number
-
구매용품아이템코드 item
-
사용자평가점수 score
사용자평가점수 score
-
구매한 아이템에 대한 사용자의 긍정 또는 부정을 스코어링
-
사용자의 취향을 알 수 있는 중요한 필드
-
구매한 제품에 대한 평가 데이터는 수많은 사용자로부터 다양하게 나타남
-
사용자에게는 기호와 취향이라는게 있음
-
이러한 기호와 취향에 따라 이력을 분석해 보면 눈에 보이지 않는 패턴이 발견됨
-
유사 패턴을 보이는 사용자 간의 유사성을 계산
-
그 결과로부터 유사 사용자 간의 선호하는 아이템을 예측하고 추천 => 사용자 기반 협업 필터링 모델
사용자 기반 협업 필터링 모델
-
사용자 A와 B가 공통으로 구매했던 물건들의 평가 점수로 유사도 측정
-
유사한 사용자로군으로 판명되면 사용자 A는 구매했으나 B는 구매하지 않은 물건 추천
"스마트카 차량용품 구매 이력" 데이터로 머하웃 추천 모델 만들기
01. 데이터 머하웃 추천기에서 사용 가능한 형식으로 재구성
-
Hue> Hive Editor > /CH07/HiveQL/2nd/그림-7-54
-
managed_smartcar_item_buylist_info > local file
-
hash() : 숫자 타입(long ) 형 변환
insert overwrite local directory '/home/pilot-pjt/mahout-data/recommendation/input'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
select hash(car_number ), hash(item), score from managed_smartcar_item_buylist_info02. Input Data 생성 확인 > Server02 > ssh >
-
ls /home/pilot-pjt/mahout/recommendation/input/
-
000000_0 파일 생성 확인
-
more /home/pilot-pjt/mahout/recommendation/input/*
-
차량번호, 상품코드, 평가점수 순 표시 확인
03. Input Data > HDFS
-
hdfs dfs -mkdir /pilot-pjt/mahout
-
hdfs dfs -mkdir /pilot-pjt/mahout/recommendation/
-
hdfs dfs -mkdir /pilot-pjt/mahout/recommendation/input
-
hdfs dfs -put /home/pilot-pjt/mahout-data/recommendation/input/* /pilot-pjt/mahout/recommendation/input/item_buylist.txt
04. mahout 명령어 실행 > /CH07/Mahout/2nd/그림7.56
-
mahout recommenditembased -i /pilot-pjt/mahout/recommendation/input/item_buylist.txt -o /pilot-pjt/mahout/recommendation/output/ -s SIMILARITY_COOCCURRENCE -n 3
-
사용된 매개변수와 옵션
-
i: 추천 분석에 상용할 입력 데이터
-
o: 추천 분석 결과가 출력될 경로
-
s: 추천을 위한 유사도 알고리즘
-
n: 추천할 아이템 개수
-
-
여러개의 잡과 과련된 맵리듀스가 반복적으로 실행되면서 수분의 시간이 소요
-
정상 완료 확인
-
Info driver.MahoutDriver: Program took ...
-
분석결과 파일 확인
-
Hue > 파일브라우저
-
/pilot-pjt/mahout/recommendation/output/
-
part-r-00000, part-r-00001
-
추천받은차량번호 / 추천상품1 :상품ID:추천값 / 추천상품2 :상품ID:추천값 / 추천상품31 :상품ID:추천값
임시파일 삭제
-
hdfs dfs -rm -R -skipTrash /pilot-pjt/mahout/recommendation/output/
-
hdfs dfs -rm -R -skipTrash /user/root/temp
머하웃 상품 추천기 활용
-
실시간 상품 추천
-
이메일 , SMS 맛춤형 프로모션
-
1:1 마케팅 등
-
아마존판매량 35%, 구글 뉴스 페이지뷰 38%가 추천에 의해 발생
머하웃 분류 - 스마트카 상태 정보 예측/분류
사용 데이터셋
-
"스마트카 상태 정보" managed_smartcar_Status_info
추천에 필요한 항목
-
스마트카 주요 장치
-
타이어, 라이트, 엔진, 브레이크 등에 대한 상태를 기록한 값
-
이 값들을 이용해 차량의 정상/비정상을 분류하는 모델 생성
-
이 모델을 실시간으로 적용 > 안정성을 분류를 통해 예측
-
알고리즘은 랜덤 포레스트 이용
랜덤 포레스트
-
단일 의사 결정 트리

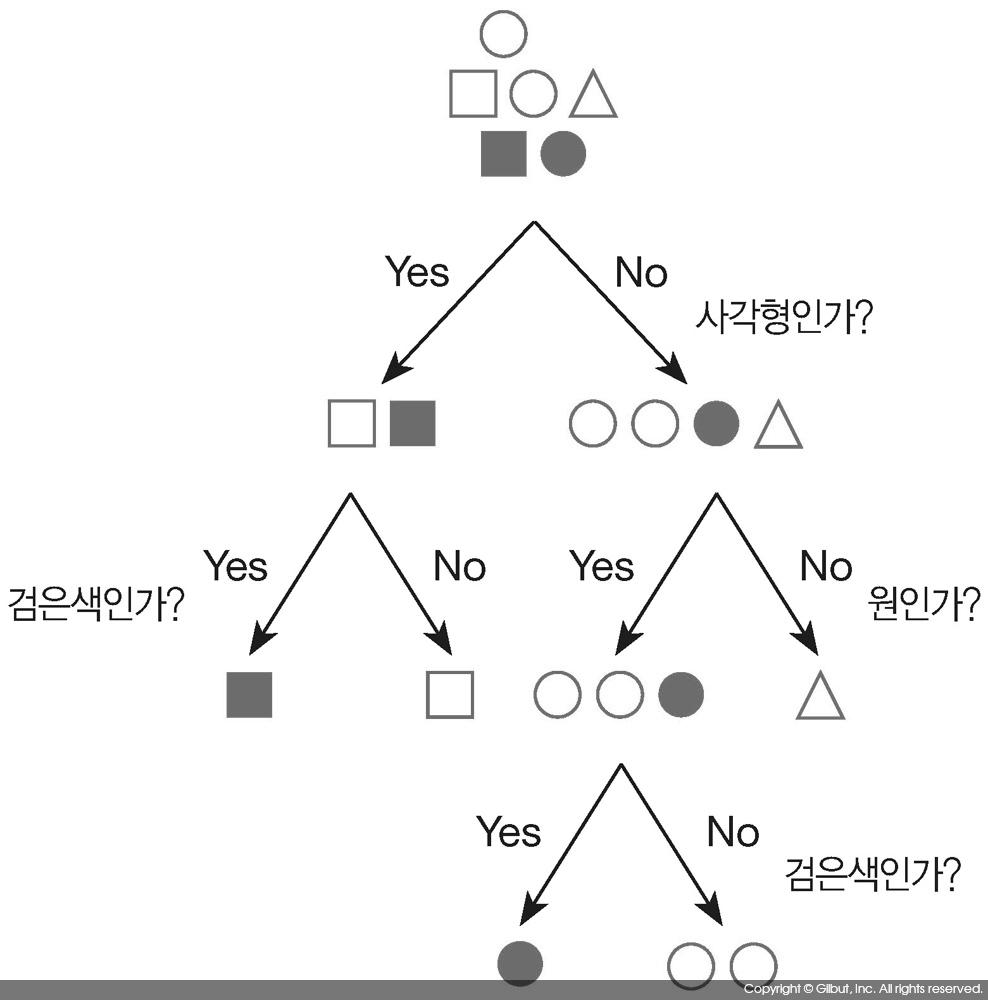
-
Random Forest

-
앙상블과 랜덤포레스트
과거의 운행했던 스마트카의 상태 데이터
-
학습(훈련, 트레이닝) 데이터로 머하웃 분류기에 제공
-
학습이 끝나면 스마트카 상태를 판단 할 수 있는 Classify 생성
-
이 Classify에 현재 운행중인 스마트카 시스템에 적용 차량 상태 예측 애플리케이션 제작
"스마트카 상태 정보" 데이터로 머하웃 추천 모델 만들기
01. 데이터 머하웃 추천기에서 사용 가능한 형식으로 재구성
-
Hue> Hive Editor > /CH07/HiveQL/2nd/그림-7-62
-
스마트카 상태 정보의 상태값으로 주관적인 기준으로 스코어링
-
예측변수의 값을 합산해서 "6"미만인 경우 비정상, "6"이상인 경우 정상인 목표변수 정의
-
Server02의 /home/pilot-pjt/mahout-data/classification/input 결과 생성
-
"'ascii' codec can't encode..." 한글 쿼리 포함 신청시 나옴, 무시해도 됨
insert overwrite local directory '/home/pilot-pjt/mahout-data/classification/input'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
select
sex, age, marriage, region, job, car_capacity, car_year, car_model,
tire_fl, tire_fr, tire_bl, tire_br, light_fl, light_fr, light_bl, light_br,
engine, break, battery,
case when ((tire_fl_s + tire_fr_s + tire_bl_s + tire_br_s +
light_fl_s + light_fr_s + light_bl_s + light_br_s +
engine_s + break_s + battery_s +
car_capacity_s + car_year_s + car_model_s) < 6)
then '비정상' else '정상'
end as status
from (
select
sex, age, marriage, region, job, car_capacity, car_year, car_model,
tire_fl, tire_fr, tire_bl, tire_br, light_fl, light_fr, light_bl, light_br,
engine, break, battery,
case
when (1500 > cast(car_capacity as int)) then -0.3
when (2000 > cast(car_capacity as int)) then -0.2
else -0.1
end as car_capacity_s ,
case
when (2005 > cast(car_year as int)) then -0.3
when (2010 > cast(car_year as int)) then -0.2
else -0.1
end as car_year_s ,
case
when ('B' = car_model) then -0.3
when ('D' = car_model) then -0.3
when ('F' = car_model) then -0.3
when ('H' = car_model) then -0.3
else 0.0
end as car_model_s ,
case
when (10 > cast(tire_fl as int)) then 0.1
when (20 > cast(tire_fl as int)) then 0.2
when (40 > cast(tire_fl as int)) then 0.4
else 0.5
end as tire_fl_s ,
case
when (10 > cast(tire_fr as int)) then 0.1
when (20 > cast(tire_fr as int)) then 0.2
when (40 > cast(tire_fr as int)) then 0.4
else 0.5
end as tire_fr_s ,
case
when (10 > cast(tire_bl as int)) then 0.1
when (20 > cast(tire_bl as int)) then 0.2
when (40 > cast(tire_bl as int)) then 0.4
else 0.5
end as tire_bl_s ,
case
when (10 > cast(tire_br as int)) then 0.1
when (20 > cast(tire_br as int)) then 0.2
when (40 > cast(tire_br as int)) then 0.4
else 0.5
end as tire_br_s ,
case when (cast(light_fl as int) = 2) then 0.0 else 0.5 end as light_fl_s ,
case when (cast(light_fr as int) = 2) then 0.0 else 0.5 end as light_fr_s ,
case when (cast(light_bl as int) = 2) then 0.0 else 0.5 end as light_bl_s ,
case when (cast(light_br as int) = 2) then 0.0 else 0.5 end as light_br_s ,
case
when (engine = 'A') then 1.0
when (engine = 'B') then 0.5
when (engine = 'C') then 0.0
end as engine_s ,
case
when (break = 'A') then 1.0
when (break = 'B') then 0.5
when (break = 'C') then 0.0
end as break_s ,
case
when (20 > cast(battery as int)) then 0.2
when (40 > cast(battery as int)) then 0.4
when (60 > cast(battery as int)) then 0.6
else 1.0
end as battery_s
from managed_smartcar_status_info ) T1
02. Input Data 생성 확인 > Server02 > ssh >
-
ls /home/pilot-pjt/mahout-data/classification/input/
-
000000_0, 000001_0 파일 생성 확인(적재 데이터 양에 따라 다름)
-
more /home/pilot-pjt/mahout-data/classification/input/*
02-1. 여러개의 파일 생성시 하나의 데이터로 합치기
-
cd /home/pilot-pjt/mahout-data/classification/input/
-
cat 000000_0 000001_0 > classification_dataset.txt
03. Input Data > HDFS
-
hdfs dfs -mkdir /pilot-pjt/mahout/classification/
-
hdfs dfs -mkdir /pilot-pjt/mahout/classification/input
-
hdfs dfs -put /home/pilot-pjt/mahout-data/classification/input/* /pilot-pjt/mahout/classification/input/classification_dataset.txt
04. mahout 명령어 실행 > /CH07/Mahout/2nd/
-
디스크립터(Descriptor) 파일 생성
-
디스크립터 파일은 학습할 데이터의 형식을 정의하는 파일
-
hadoop jar /opt/cloudera/parcels/CDH/lib/mahout/mahout-examples-job.jar org.apache.mahout.classifier.df.tools.Describe -p /pilot-pjt/mahout/classification/input/classification_dataset.txt -f /pilot-pjt/mahout/classification/output/descriptor/smartcar-status.descriptor -d I I I I I N N C N N N N N N N N C C N L
-
실행성공: storing the dataset description
-
사용된 매개변수와 옵션
-
p: 트레이닝에 사용할 데이터셋 경로
-
f: 디스크립터 파일이 생성될 경로
-
d: 트레이닝에 사용할 데이터셋의 형식 지정(I:무시, N:숫자, C:분류문자열, L:목표변수)
-
| 성별 | 나이 | 결혼여부 | 거주지 | 직업 | 차량CC | 차량연식 | 차량모델 | 타이어상태 | 라이트상태 | 엔진상태 | 브레이크상태 | 배터리상태 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C | N | C | C | C | N | N | C | N,N,N,N | N,N,N,N | C | C | N |
디스크립터(Descriptor) 파일 생성 확인
-
Hue > 파일 브라우저 > /pilot-pjt/mahout/classification/output/descriptor
-
smartcar-status.descriptor
-
05. 입력데이터셋 > 학습데이터셋, 테스트데이터셋 생성
-
7:3 또는 8:2 비율로 분할 생성
-
머하웃의 split 명령 실행
-
mahout split -i /pilot-pjt/mahout/classification/input --trainingOutput /pilot-pjt/mahout/classification/input/training --testOutput /pilot-pjt/mahout/classification/input/testing --randomSelectionPct 30 --overwrite --method sequential
-
사용된 매개변수와 옵션
-
i: 분할(Split)시킬 원천 파일 경로
-
trainingOutput: 학습 데이터셋 생성 경로
-
testOutput: 테스트 데이터셋 생성 경로
-
randomSelectionPct: 학습 및 테스트 데이터셋 비율 지정
-
overwrite: 결과 덮어 쓰기
-
method: 분할 방식을 지정
-
학습데이터셋, 테스트데이터셋 생성 확인
-
Hue > 파일 브라우저 > /pilot-pjt/mahout/classification/input
-
testing, training 디렉토리에 classification_dataset.txt 생성 확인
06. 스마트카 상태 정보 예측 분류 모델 생성
-
트레이닝 데이터셋과 분류알고리즘 중 랜덤 포레스트로 모델 트레이닝
-
입력데이터 : 디스크립터 파일, 트레이닝 파일
-
hadoop jar /opt/cloudera/parcels/CDH/lib/mahout/mahout-examples-job.jar org.apache.mahout.classifier.df.mapreduce.BuildForest -Dmapred.max.split.size=1874231 -d /pilot-pjt/mahout/classification/input/training/classification_dataset.txt -ds /pilot-pjt/mahout/classification/output/descriptor/smartcar-status.descriptor -sl 7 -p -t 100 -o /pilot-pjt/mahout/classification/output/model
-
사용된 매개변수와 옵션
-
Dmapred.max.split.size: 맵 생성 단위를 파일 크기로 지정
-
d: 트레이닝 데이터셋 경로
-
ds: 디스크립터 파일 경로
-
sl: 의사결정 트리(Decision Tree)에 사용할 변수 개수를 지정
-
p: 트레이닝 시 데이터를 분할해서 실행
-
t: 모델에 포함될 의사결정 트리 개수를 지정
-
o: 분류기 모델 생성 경로
-
스마트카 상태 정보 예측 분류 모델 생성 확인
-
Hue > 파일 브라우저 > /pilot-pjt/mahout/classification/model
-
testing, training 디렉토리에 classification_dataset.txt 생성 확인
07. 스마트카 상태 정보 예측 분류 모델 평가
-
입력 테스트데이터셋: /pilot-pjt/mahout/classification/input/testing/classification_dataset.txt
-
hadoop jar /opt/cloudera/parcels/CDH/lib/mahout/mahout-examples-job.jar org.apache.mahout.classifier.df.mapreduce.TestForest -i /pilot-pjt/mahout/classification/input/testing/classification_dataset.txt -ds /pilot-pjt/mahout/classification/output/descriptor/smartcar-status.descriptor -m /pilot-pjt/mahout/classification/output/model -a -mr -o /pilot-pjt/mahout/classification/output/predictions
-
사용된 매개변수와 옵션
-
i: 테스트(평가) 데이터셋 경로
-
ds: 디스크립터 파일 경로
-
m: 분류기 모델 파일 경로
-
a: 평가결과 표준 출력
-
mr: 맵리듀스 기반 평가 동작
-
o: 평가 결과 출력 경로
-
스마트카 상태 정보 예측 분류 모델 평가 결과
-
Correctly Classified Instances : 분류 성공율
-
Incorrectly Classified Instances: 분류 실패율
-
Confusion Matrix: 비정상(a), 정상(b)의 분류 케이스를 메트릭스로 표현
-
예측결과위치 : /pilot-pjt/mahout/classification/output/predictions
07. 스마트카 상태 정보 예측 프로그램에 적용 - Java Application
-
전체프로그램: /workspace/bigdata.smartcar.mahout/*
ClassifySmartCarStatus.java
분류기 모델 저장 위치
DecisionForest classifyModel = DecisionForest.load(
config, new Path("./classification/model/forest.seq"));디스크립터 파일 저장 위치
Dataset dataset = Dataset.load(
config, new Path("./classification/descriptor/smartcar-status.descriptor"));입력값 분류를 위한 벡터 데이터셋 설정
DenseVector car_vector = new DenseVector(14);
car_vector.set(0, Integer.parseInt(args[i++])); //car_capacity
car_vector.set(1, Integer.parseInt(args[i++])); //car_year
car_vector.set(2, dataset.valueOf(2, args[i++])); //car_model
car_vector.set(3, Integer.parseInt(args[i++])); //타이어 1
car_vector.set(4, Integer.parseInt(args[i++])); //타이어 2
car_vector.set(5, Integer.parseInt(args[i++])); //타이어 3
car_vector.set(6, Integer.parseInt(args[i++])); //타이어 4
car_vector.set(7, Integer.parseInt(args[i++])); //라이트 1
car_vector.set(8, Integer.parseInt(args[i++])); //라이트 2
car_vector.set(9, Integer.parseInt(args[i++])); //라이트 3
car_vector.set(10, Integer.parseInt(args[i++])); //라이트 4
car_vector.set(11, dataset.valueOf(11, args[i++])); //엔진
car_vector.set(12, dataset.valueOf(12, args[i++])); //브레이크
car_vector.set(13, Integer.parseInt(args[i++])); //베터리분류기 모델(Classify)를 작동시켜 스마트카 상태 정보 입력값에 대한 분류(정사/비정상) 예측
Instance instance = new Instance(car_vector);
Random rNum = RandomUtils.getRandom();
double prediction = classifyModel.classify(dataset, rNum, instance);분류 결과 출력
System.out.println(" SmartCar Status Prediction :"+dataset.getLabelString(prediction));애플리케이션 서버 업로드
-
어플리케이션 : /CH07/bigdata.smartcar.mahout-1.0.jar
-
업로드 :Server02/home/pilot-pjt/mahout-data/
디스크립터, 분류기 파일 Get
-
mkdir /home/pilot-pjt/mahout-data/classification/descriptor
-
mkdir /home/pilot-pjt/mahout-data/classification/model
-
cd /home/pilot-pjt/mahout-data/classification/descriptor
-
hdfs dfs -get /pilot-pjt/mahout/classification/output/descriptor/smartcar-status.descriptor
-
cd /home/pilot-pjt/mahout-data/classification/model
-
hdfs dfs -get /pilot-pjt/mahout/classification/output/model/forest.seq
애플리케이션 테스트
-
cd /home/pilot-pjt/mahout-data/
-
java -cp bigdata.smartcar.mahout-1.0.jar com.wikibook.bigdata.smartcar.mahout.ClassifySmartCarStatus 2000 2000 A 80 80 80 1 1 1 1 A B 50
-
java -cp bigdata.smartcar.mahout-1.0.jar com.wikibook.bigdata.smartcar.mahout.ClassifySmartCarStatus 2000 2000 A 80 80 80 1 1 1 1 A B 80
-
14개의 인자값
| 성별 | 나이 | 결혼여부 | 거주지 | 직업 | 차량CC | 차량연식 | 차량모델 | 타이어상태 | 라이트상태 | 엔진상태 | 브레이크상태 | 배터리상태 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C | N | C | C | C | N | N | C | N,N,N,N | N,N,N,N | C | C | N |
-
인자값을 다양하게 바꿔가면서 예측 결과 테스트
-
실제 분류기를 적용할 때는 지속적인 학습을 거쳐 Classify 프로그램 정확도 높이는 과정 중요
머하웃 군집 - 스마트카 고객 정보 분석
사용 데이터셋
-
"스마트카 고객 마스트 정보" 하이브 External 영역의 SmartCar_Master
데이터군집과 데이터셋 정보
-
스마트카 차량번호, 차량용량, 차량모델 정보
-
스마트카 사용자 성별, 나이, 결혼여부,직업, 거주지역들 정보
-
군집은 이 값들을 백터화하고 유사도 및 거리를 계산해 새로운 군집을 발견하는 마이닝 기법


-
http://wiki.gurubee.net/pages/viewpage.action?pageId=28118055
-
알고리즘 Canopy로 대략적인 군집 개수(K)와 센트로이드(중식점) 파악
-
Canopy 군집값으로 알고리즘 K-Means 적용
-
K-Means 분석 결과로 N개의 군집별로 스마트카 차량번호 리스트 확인
-
군집된 차량들 사이에 어떠한 공통적인 특징이 있는지 분석
"스마트카 마스터 정보" 데이터로 머하웃 군집 모델 만들기
01. "스마트카 마스터 정보" 데이터 셋 > 로컬 저장
-
Hue> Hive Editor > /CH07/HiveQL/2nd/그림-7-75
-
smartcar_master > local file
-
편차카 큰 변수 범주화
-
차량용량(car_capacity)
-
차령연도(car_year)
-
운전자나이 (age)
-
범주화해서 군집의 정활도를 높입
-
insert overwrite local directory '/home/pilot-pjt/mahout-data/clustering/input'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' '
select
car_number,
case
when (car_capacity < 2000) then '소형'
when (car_capacity < 3000) then '중형'
when (car_capacity < 4000) then '대형'
end as car_capacity,
case
when ((2016-car_year) <= 4) then 'NEW'
when ((2016-car_year) <= 8) then 'NORMAL'
else 'OLD'
end as car_year ,
car_model,
sex as owner_sex,
floor (cast(age as int) * 0.1 ) * 10 as owner_age,
marriage as owner_marriage,
job as owner_job,
region as owner_region
from smartcar_master 02. Input Data 생성 확인 > Server02 > ssh >
-
ls /home/pilot-pjt/mahout-data/clustering/input/
-
000000_0 파일 생성 확인
-
more /home/pilot-pjt/mahout-data/clustering/input/*
-
차량번호, 상품코드, 평가점수 순 표시 확인
03. Input Data > HDFS
-
hdfs dfs -mkdir /pilot-pjt/mahout/clustering/
-
hdfs dfs -mkdir /pilot-pjt/mahout/clustering/input
-
hdfs dfs -put /home/pilot-pjt/mahout-data/clustering/input/000000_0 /pilot-pjt/mahout/clustering/input/
-
Hue > 파일브라우저로 적재 확인
04. input Data > 시퀀스 파일로 변환
-
시퀀스 파일은 키/값 형식의 바이너리 데이터셋
-
분산환경에서 성능과 용량의 효율성을 높인 포맷
-
key: 차량번호
-
value: 차량연도,차량용량,모델,나이,연령등으로 구성
-
시퀀스 파일로 변환 애플리케이션 실행
-
hadoop jar /home/pilot-pjt/mahout-data/bigdata.smartcar.mahout-1.0.jar com.wikibook.bigdata.smartcar.mahout.TextToSequence /pilot-pjt/mahout/clustering/input/000000_0 /pilot-pjt/mahout/clustering/output/seq
-
-
시퀀스 파일 생성 확인
-
Hue > 파일 브라우저 > /pilot-pjt/mahout/clustering/output/seq
-
part-m-000000 파일 생성 확인
-
hdfs dfs -text /pilot-pjt/mahout/clustering/output/seq/part-m-000000
-
05. 시퀀스 파일 > n-gram 기반 벡터데이터로 변환
-
n-gram 벡터 모델은 단어의 분류와 빈도 수를 측정하는 알고리즘
-
차량번호별 각 항목의 단어를 분리해 벡터화하기 위해 사용
-
mahout 명령어 실행 > /CH07/Mahout/2nd/그림7.56
-
mahout seq2sparse -i /pilot-pjt/mahout/clustering/output/seq -o /pilot-pjt/mahout/clustering/output/vec -wt tf -s 5 -md 3 -ng 2 -x 85 --namedVector
-
사용된 매개변수와 옵션
-
wt: 단어 빈도 가중치 방식
-
md: 최소 문서 출현 횟수
-
ng: ngrams 최댓값
-
nameVector: 네입벡터 데이터 생성
-
-
파일 생성 확인
-
Hue > 파일 브라우저 > /pilot-pjt/mahout/clustering/output/vec
-
df-count, tf-vectors 등 생성 됨
-
06. Canopy 군집 분석
-
군집의 갯수 파악을 위해 t1, t2의 옵션을 변경하며 반복적인 군집분석 수행
-
mahout canopy -i /pilot-pjt/mahout/clustering/output/vec/tf-vectors/ -o /pilot-pjt/mahout/clustering/canopy/out -dm org.apache.mahout.common.distance.SquaredEuclideanDistanceMeasure -t1 50 -t2 45 -ow
-
사용된 매개변수와 옵션
-
i: 벡터 파일 경로
-
o: 출력 결과 경로
-
dm: 군집 측청 알고리즘
-
t1: 거리값 1
-
t2: 거리값 2
-
Canopy 군집 결과 확인
-
mahout clusterdump -i /pilot-pjt/mahout/clustering/canopy/out/clusters-*-final
-
INFO clustering.ClusterDump : wrote 1 cluster
-
t1, t2 초기 거리값이 너무 커서 1개의 군집만 만들어짐(2600명)
Canopy 군집 재실행 및 결과 확인
-
mahout canopy -i /pilot-pjt/mahout/clustering/output/vec/tf-vectors/ -o /pilot-pjt/mahout/clustering/canopy/out -dm org.apache.mahout.common.distance.SquaredEuclideanDistanceMeasure -t1 10 -t2 8 -ow
-
mahout clusterdump -i /pilot-pjt/mahout/clustering/canopy/out/clusters-*-final
-
INFO clustering.ClusterDump : wrote 819 cluster
-
t1, t2 초기 거리값이 너무 작어 819개의 군집 만들어짐(2600명)
Canopy 군집 재실행 및 결과 확인
-
mahout canopy -i /pilot-pjt/mahout/clustering/output/vec/tf-vectors/ -o /pilot-pjt/mahout/clustering/canopy/out -dm org.apache.mahout.common.distance.SquaredEuclideanDistanceMeasure -t1 12 -t2 10 -ow
-
mahout clusterdump -i /pilot-pjt/mahout/clustering/canopy/out/clusters-*-final
-
INFO clustering.ClusterDump : wrote 819 cluster
-
t1, t2 초기 거리값이 너무 작어 148개의 군집 만들어짐(2600명)
-
군집의 적절 수는 주관적이며 분석 요건과 데이터 성격에 따라 적절한 군집의 개수 판단 필요
06. K-Means 군집 분석
-
초기 군집값 필요(K)
-
mahout kmeans -i /pilot-pjt/mahout/clustering/output/vec/tf-vectors -c /pilot-pjt/mahout/clustering/kmeans/output/cluster -o /pilot-pjt/mahout/clustering/kmeans/output -dm org.apache.mahout.common.distance.SquaredEuclideanDistanceMeasure -cd 1.0 -k 200 -x 20 -cl -xm mapreduce -ow
-
사용된 매개변수와 옵션
-
i: 벡터 파일 경로
-
c: 초기 클러스터 데이터 생성 경로
-
o: 출력 결과 경로
-
dm: 군집 거리 측청 알고리즘
-
cd: 수렴할 임계값 지정
-
k: 군집수 지정
-
x:최대 반복 수행 횟수
-
xm:실행 방식 지정
-
K-Means 결과 파일 생성
-
mahout clusterdump -i /pilot-pjt/mahout/clustering/kmeans/output/clusters-*-final -p /pilot-pjt/mahout/clustering/kmeans/output/clustersPoints -o /home/pilot-pjt/mahout-data/clustering/output/clusterdump_result.txt
K-Means 결과 파일 확인
-
more /home/pilot-pjt/mahout-data/clustering/output/clusterdump_result.txt
-
VL-aaaa : 클러스트 이름
-
n=11 : 클러스트에 포함된 대상의 개수
-
c={1:0.91...}: 클러스트 중심값
-
r={1:0.287}: 클러스트 반경
-
결과 확인을 위해 임의의 클러스트명 확인 :VL-1418
군집형성 주요 키워드 파일 생성
-
touch /home/pilot-pjt/mahout-data/clustering/output/clusterdump_result2.txt 생성
-
mahout clusterdump 명령 사용
-
mahout clusterdump -dt sequencefile -d /pilot-pjt/mahout/clustering/output/vec/dictionary.file-* -i /pilot-pjt/mahout/clustering/kmeans/output/clusters-*-final -o /home/pilot-pjt/mahout-data/clustering/output/clusterdump_result2.txt -b 10 -n 10 -dm org.apache.mahout.common.distance.SquaredEuclideanDistanceMeasure
VL-1234 군집형성 주요 키워드 값 확인
-
grep -11 ":VL-1418" /home/pilot-pjt/mahout-data/clustering/output/clusterdump_result2.txt
-
군집 VL-1418은 여(성별), 기혼(결혼여부), b(차량모델), old(차량년도) 순으로 군집에 영향
군집에 포함된 차량 추출
-
/home/pilot-pjt/mahout-data/clustering/output/clusterdump_result2.txt 생성
-
mahout clusterdump 명령 사용
-
mahout seqdumper -i /pilot-pjt/mahout/clustering/kmeans/output/clusteredPoints/ -o /home/pilot-pjt/mahout-data/clustering/output/seqdumper_result.txt
VL-1234 군집형성 주요 키워드 값 확인
-
grep "Key: 1418" /home/pilot-pjt/mahout-data/clustering/output/seqdumper_result.txt
-
11대의 스마트카 차량번호가 유사성이있어 군집으로 형성된 차량
VL-1234 군집형성 차량번호로 데이터 확인
-
Hue > QE > Hive
-
select car_number,sex,age,car_capacity,car_year,car_model from smartcar_master where car_number in( 'C0029', 'C0052', 'E0050', 'H0082', 'M0085','O0019', 'P0074', 'S0062', 'V0055', 'Y0035', 'Z0001' )
VL-1234 군집 인사이트 도출
-
고객군은 50대 기혼 여성으로 스마트카 B모델 선호
-
고객군의 차량은 중,대형 차량으로 소득 수준이 높은 것으로 추측
-
이 고객군과 유사한 고객군은 스마트카 B모델 또는 유사 모델로 타깃 마케팅
분석 파일럿 실행 6단계 - 스쿱을 이용한 분석 결과 외부 제공
-
빅데이터 시스템에서 탐색 및 분석한 결과를 외부 업무시스템(RDBMS)에 제공
-
제공된 데이터는 중요한 의사결정 포인트로 사용
스쿱의 내보내기 기능 - 이상 운전 차량 정보
-
Hive => PostgreSQL
-
Export 테이블: Hive Maanged 영역 Managed_SmartCar_Symptom_Info
사용 DBMS 정보
-
서버 : 192.168.56.101
-
포토: 7432
-
DB Name: postgres
-
ID: cloudera-scm
-
PWD: 각 설치환경 확인
-
cat /var/lib/cloudera-scm-server-db/data/generated_password.txt
PostgreSQL 접속
-
psql -U cloudera-scm -p 7432 -h localhost -d postgres
-
postgres=# 확인
PostgreSQL 테이블 생성
-
postgres=# create table smartcar_symptom_info ( car_number varchar, speed_p_avg varchar, speed_p_symptom varchar, break_p_avg varchar, break_p_symptom varchar, steer_a_cnt varchar, steer_p_symptom varchar, biz_date varchar );
-
postgres=# select * from smartcar_symptom_info;
Server01에서 스쿱 실행
-
Server01 sshd 접속
-
PostgreSQL JDBC Driver > Sqoop lib 폴더로 복사
-
cp /opt/cloudera/parcels/CDH/jars/postgresql-9.0-801.jdbc4.jar /opt/cloudera/parcels/CDH/lib/sqoop/lib/
-
su hdfs
-
스쿱 내보내기 명령 실행(패스워드 주의!!!!)
-
sqoop export --connect jdbc:postgresql://127.0.0.1:7432/postgres --username cloudera-scm --password BjiYCUGDda --table smartcar_symptom_info --export-dir /user/hive/warehouse/managed_smartcar_symptom_info
-
사용된 매개변수와 옵션
-
username: PostgreSQL 계정
-
password: PostgreSQL 비번
-
table: PostgreSQL 입력 받을 테이블
-
export-dir: export 할 HDFS 경로
-
-
postgres=# select * from smartcar_symptom_info;
-
postgres=# \q
필요시 RDBMS 데이터 제공 잡업도 휴 워크플로우를 생성 정기적인 작업 수행