R
기술통계 - 실전 예제
긔
2020. 7. 7. 15:20
기술 통계
실전 예제
전국 연령별 평균 월급 조사
# 데이터 로드
# 통계청 2013년 발표 연령, 남녀, 경력별 평균월급 데이터셋
df <- read.csv("r-ggagi-data/example_salary.csv", stringsAsFactors = T, na = '-') # - 값은 NA로 바꾸기head(df)| 연령 | 월급여액..원. | 연간특별급여액..원. | 근로시간..시간. | 근로자수..명. | 경력구분 | 성별 |
|---|---|---|---|---|---|---|
| -19 | 1346534 | 151840 | 169.5 | 15042 | 1년미만 | 남 |
| 20-24 | 1584214 | 115375 | 180.1 | 74251 | 1년미만 | 남 |
| 25-29 | 1922043 | 268058 | 178.0 | 143338 | 1년미만 | 남 |
| 30-34 | 2130988 | 335710 | 180.8 | 103585 | 1년미만 | 남 |
| 35-39 | 2414345 | 352816 | 181.4 | 65385 | 1년미만 | 남 |
| 40-44 | 2372214 | 233728 | 182.9 | 55422 | 1년미만 | 남 |
# 한글 변수명 => 영문으로 바꾸기
colnames(df)
colnames(df) <- c('age','salary','specialSalary','workingTime','numberOfWorker','career','gender')- '연령'
- '월급여액..원.'
- '연간특별급여액..원.'
- '근로시간..시간.'
- '근로자수..명.'
- '경력구분'
- '성별'
colnames(df)- 'age'
- 'salary'
- 'specialSalary'
- 'workingTime'
- 'numberOfWorker'
- 'career'
- 'gender'
# 평균 월급 구하기
Mean <- mean(df$salary, na.rm = T)
Mean2171577.83673469
# 아웃라이어 영향이 있는지 월 중앙값 계산
Median <- median(df$salary, na.rm = T)
Median2120345
# 범위 구하기
Range <- range(df$salary, na.rm = T)
Range- 1117605
- 4064286
# 4064286 월급 연령대, 성별, 경력 확인
w <- which(df$salary == 4064286)
w48
df[w,]| age | salary | specialSalary | workingTime | numberOfWorker | career | gender | |
|---|---|---|---|---|---|---|---|
| 48 | 50-54 | 4064286 | 12716896 | 178.2 | 439450 | 10년이상 | 남 |
# 월급 4분위 수
Quantile <- quantile(df$salary, na.rm = T)
Quantile- 0%
- 1117605
- 25%
- 1689658.25
- 50%
- 2120345
- 75%
- 2519221.25
- 100%
- 4064286
# 리스트에 데이터 담기 / R에서의 list는 다양한 데이터를 담을 수 있다
Salary <- list(평균=Mean, 중앙값=Median, 범위=Range, 사분위=Quantile)
Salary- $평균
- 2171577.83673469
- $중앙값
- 2120345
- $범위
-
- 1117605
- 4064286
- $사분위
-
- 0% 1117605
- 25% 1689658.25
- 50% 2120345
- 75% 2519221.25
- 100% 4064286
그룹별 평균 구하기
# 데이터 확인
head(df)| age | salary | specialSalary | workingTime | numberOfWorker | career | gender |
|---|---|---|---|---|---|---|
| -19 | 1346534 | 151840 | 169.5 | 15042 | 1년미만 | 남 |
| 20-24 | 1584214 | 115375 | 180.1 | 74251 | 1년미만 | 남 |
| 25-29 | 1922043 | 268058 | 178.0 | 143338 | 1년미만 | 남 |
| 30-34 | 2130988 | 335710 | 180.8 | 103585 | 1년미만 | 남 |
| 35-39 | 2414345 | 352816 | 181.4 | 65385 | 1년미만 | 남 |
| 40-44 | 2372214 | 233728 | 182.9 | 55422 | 1년미만 | 남 |
# 성별 평균월급 - tapply() : group by
temp <- tapply(df$salary, df$gender, mean, na.rm = T)
temp- 남
- 2477332.3877551
- 여
- 1865823.28571429
library('reshape2')
library('ggplot2')
# 재 구조화 그냥 temp로는 그래프 작업 불가
melt <- melt(temp)
melt
# 그래프로 확인
ggplot(melt, aes(x=Var1, y=value, fill=Var1)) + geom_bar(stat='identity')Warning message:
"package 'reshape2' was built under R version 3.6.3"Warning message:
"package 'ggplot2' was built under R version 3.6.3"| Var1 | value |
|---|---|
| 남 | 2477332 |
| 여 | 1865823 |
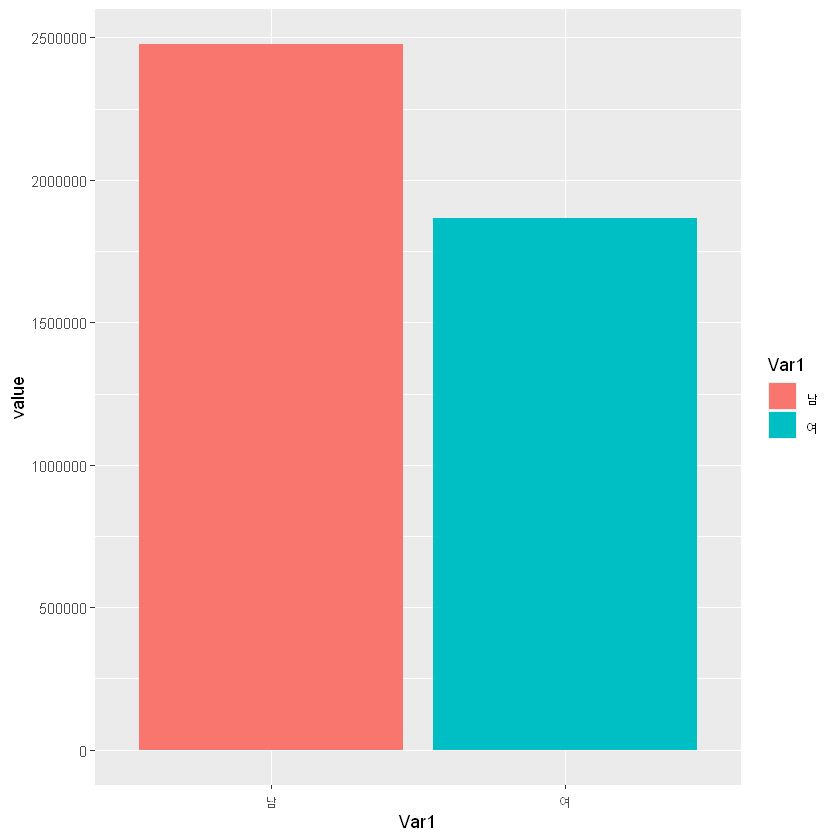
# 표준편차 - 남 월급도 높고, 격차도 큼
tapply(df$salary, df$gender, sd, na.rm=T)- 남
- 646470.66723018
- 여
- 468270.600001128
# 범위
tapply(df$salary, df$gender, range, na.rm=T)- $남
-
- 1346534
- 4064286
- $여
-
- 1117605
- 3002440
# 경력별 평균월급
temp <- tapply(df$salary, df$career, mean, na.rm=T)
temp- 1~3년미만
- 1905011.9
- 10년이상
- 2907118.61111111
- 1년미만
- 1730835.35
- 3~5년미만
- 2028014.9
- 5~10년미만
- 2360462.5
# 그래프로 확인
melt <- melt(temp)
melt
ggplot(melt, aes(x=Var1, y=value, group=1))+
geom_line(colour='skyblue2', size=2) +
coord_polar() +
ylim(0, max(melt$value))| Var1 | value |
|---|---|
| 1~3년미만 | 1905012 |
| 10년이상 | 2907119 |
| 1년미만 | 1730835 |
| 3~5년미만 | 2028015 |
| 5~10년미만 | 2360463 |

# 표준편차
tapply(df$salary, df$career, sd, na.rm=T)- 1~3년미만
- 421332.817832436
- 10년이상
- 690976.727993927
- 1년미만
- 408110.437480279
- 3~5년미만
- 460790.871315817
- 5~10년미만
- 507244.739786116
# 범위
tapply(df$salary, df$career, range, na.rm=T)- $`1~3년미만`
-
- 1172399
- 2619221
- $`10년이상`
-
- 1685204
- 4064286
- $`1년미만`
-
- 1117605
- 2414345
- $`3~5년미만`
-
- 1245540
- 2827420
- $`5~10년미만`
-
- 1548036
- 3309231
# 경력별 가장 월급이 작은 그룹 - 경력 1~3, 여 나이 60 이상
a1 <- df[which(df$salary == '1172399'),]
a1| age | salary | specialSalary | workingTime | numberOfWorker | career | gender | |
|---|---|---|---|---|---|---|---|
| 70 | 60- | 1172399 | 299639 | 151.2 | 30253 | 1~3년미만 | 여 |
# 경력별 가장 월급이 작은 그룹 - 경력 10년 이상, 여 나이 20~24
a2 <- df[which(df$salary == '1685204'),]
a2| age | salary | specialSalary | workingTime | numberOfWorker | career | gender | |
|---|---|---|---|---|---|---|---|
| 92 | 20-24 | 1685204 | 1970720 | 179.4 | 1886 | 10년이상 | 여 |
# 경력별 가장 월급이 작은 그룹 - 경력 1년미만, 여 나이 60이상
a3 <- df[which(df$salary == '1117605'),]
a3| age | salary | specialSalary | workingTime | numberOfWorker | career | gender | |
|---|---|---|---|---|---|---|---|
| 60 | 60- | 1117605 | 10667 | 148 | 18737 | 1년미만 | 여 |
# 경력별 가장 월급이 작은 그룹 - 경력 3~5년미만, 여 나이 60이상
a4 <- df[which(df$salary == '1245540'),]
a4| age | salary | specialSalary | workingTime | numberOfWorker | career | gender | |
|---|---|---|---|---|---|---|---|
| 80 | 60- | 1245540 | 423826 | 155.1 | 21106 | 3~5년미만 | 여 |
# 경력별 가장 월급이 작은 그룹 - 경력 5~10년미만, 여 나이 60이상
a5 <- df[which(df$salary == '1548036'),]
a5| age | salary | specialSalary | workingTime | numberOfWorker | career | gender | |
|---|---|---|---|---|---|---|---|
| 90 | 60- | 1548036 | 806919 | 169.1 | 20282 | 5~10년미만 | 여 |
아웃라이어 찾기와 제거하기
-
대장암 관련 데이터 사용
# 데이터 로드
df <- read.csv('r-ggagi-data/example_cancer.csv', stringsAsFactors = F, na='기록없음')# 요약 확인
str(df)'data.frame': 18310 obs. of 8 variables:
$ age : int 75 52 67 62 70 76 55 72 64 71 ...
$ sex : chr "남" "여" "여" "남" ...
$ height : num 161 177 154 162 171 ...
$ weight : num 64 75.3 65.6 57 65 87 77 55 67 55.5 ...
$ dateOfoperation: chr "2011-06-22" "2011-05-19" "2011-05-31" "2011-06-21" ...
$ cancerStaging : chr "I" "IV" "III" "I" ...
$ hospitalization: int 48 17 10 11 10 10 12 18 15 35 ...
$ diseaseCode : chr "C187" "C187" "C187" "C187" ...# 대장암에 걸리는 평균 나이
mean(df$age)63.5079191698525
# age 특징확인
summary(df$age) Min. 1st Qu. Median Mean 3rd Qu. Max.
18.00 55.00 64.00 63.51 72.00 102.00 # 시각화
boxplot(df$age)
# 100세 이상, 30세 이하는 잘 안걸림
# IQR(InterQuantile Range) * 1.5 = 아웃라이어(이상치)
dist_iqr <- IQR(df$age, na.rm=T)
dist_iqr17
# IQR위치 확인
post_iqr <- quantile(df$age, probs = c(0.25, 0.75), na.rm=T)
post_iqr- 25%
- 55
- 75%
- 72
# whisker = 수염
down_whisker <- post_iqr[[1]] - dist_iqr*1.5
up_whisker <- post_iqr[[2]] + dist_iqr*1.5down_whisker
up_whisker29.5
97.5
outlier <- subset(df, subset=(df$age < down_whisker | df$age > up_whisker))
str(outlier)'data.frame': 62 obs. of 8 variables:
$ age : int 29 28 29 25 24 28 29 28 24 102 ...
$ sex : chr "남" "남" "남" "여" ...
$ height : num 162 151 166 177 161 ...
$ weight : num 70.6 44.9 57.3 73.6 64.1 61 55 63.3 79 62.5 ...
$ dateOfoperation: chr "2011-05-17" "2011-08-02" "2011-09-06" "2011-11-10" ...
$ cancerStaging : chr "II" "I" "II" "II" ...
$ hospitalization: int 24 8 9 10 19 7 11 57 19 16 ...
$ diseaseCode : chr "C184" "C187" "C187" "C184" ...head(outlier)| age | sex | height | weight | dateOfoperation | cancerStaging | hospitalization | diseaseCode | |
|---|---|---|---|---|---|---|---|---|
| 426 | 29 | 남 | 162.0 | 70.6 | 2011-05-17 | II | 24 | C184 |
| 531 | 28 | 남 | 151.4 | 44.9 | 2011-08-02 | I | 8 | C187 |
| 902 | 29 | 남 | 165.8 | 57.3 | 2011-09-06 | II | 9 | C187 |
| 1042 | 25 | 여 | 176.9 | 73.6 | 2011-11-10 | II | 10 | C184 |
| 1299 | 24 | 남 | 161.0 | 64.1 | 2011-08-05 | IV | 19 | C187 |
| 1783 | 28 | 여 | 154.0 | 61.0 | 2011-05-27 | IV | 7 | C188 |
평균값을 표준화하여 그래프 한 눈에 보기
-
통계청 월급 정보 사용
# 데이터 로드
df <- read.csv('r-ggagi-data/example_salary.csv', stringsAsFactors = F, na='-')# 한글 변수명 => 영문으로 바꾸기
colnames(df)
colnames(df) <- c('age','salary','sepcialSalary','workingTime','numberOfWorker','career','gender')- '연령'
- '월급여액..원.'
- '연간특별급여액..원.'
- '근로시간..시간.'
- '근로자수..명.'
- '경력구분'
- '성별'
# 표준화 - scale()
salary_scale <- scale(df$salary)
head(salary_scale)| -1.28886999 |
| -0.91757018 |
| -0.38981924 |
| -0.06340878 |
| 0.37924689 |
| 0.31343053 |
# 표준화 값 추가
df_scale <- cbind(df, scale=salary_scale)
head(df_scale)| age | salary | sepcialSalary | workingTime | numberOfWorker | career | gender | scale |
|---|---|---|---|---|---|---|---|
| -19 | 1346534 | 151840 | 169.5 | 15042 | 1년미만 | 남 | -1.28886999 |
| 20-24 | 1584214 | 115375 | 180.1 | 74251 | 1년미만 | 남 | -0.91757018 |
| 25-29 | 1922043 | 268058 | 178.0 | 143338 | 1년미만 | 남 | -0.38981924 |
| 30-34 | 2130988 | 335710 | 180.8 | 103585 | 1년미만 | 남 | -0.06340878 |
| 35-39 | 2414345 | 352816 | 181.4 | 65385 | 1년미만 | 남 | 0.37924689 |
| 40-44 | 2372214 | 233728 | 182.9 | 55422 | 1년미만 | 남 | 0.31343053 |
# 시각화
g1 <- ggplot(df_scale, aes(x=scale, y=age))
g2 <- geom_segment(aes(yend=age), xend=0)
g3 <- geom_point(size=7, aes(colour=gender, shape=career))
g1 + g2 + g3 + theme_minimal()Warning message:
"Removed 2 rows containing missing values (geom_segment)."Warning message:
"Removed 2 rows containing missing values (geom_point)."