Python
Python - CSV 활용
긔
2020. 5. 28. 18:36
CSV Data 읽고 쓰기(Reading & Writing CSV Data)
읽기(Reading)
stocks.csv
stocks.csv
Symbol,Price,Date,Time,Change,Volume
"AA",39.48,"6/11/2007","9:36am",-0.18,181800
"AIG",71.38,"6/11/2007","9:36am",-0.15,195500
"AXP",62.58,"6/11/2007","9:36am",-0.46,935000
"BA",98.31,"6/11/2007","9:36am",+0.12,104800
"C",53.08,"6/11/2007","9:36am",-0.25,360900
"CAT",78.29,"6/11/2007","9:36am",-0.23,225400csv library 사용
import csv
with open('stocks.csv') as f:
f_csv = csv.reader(f)
headers = next(f_csv)
for row in f_csv:
# Process row
#print(row)
print('basic : %s %s ' % (row[0], row[4]))-
row 는 list 자료형
-
인덱싱으로 자료 처리(indexing)
-
row[0] (Symbol) and row[4] (Change).
-
인덱싱은 종종 혼동을 일으킴
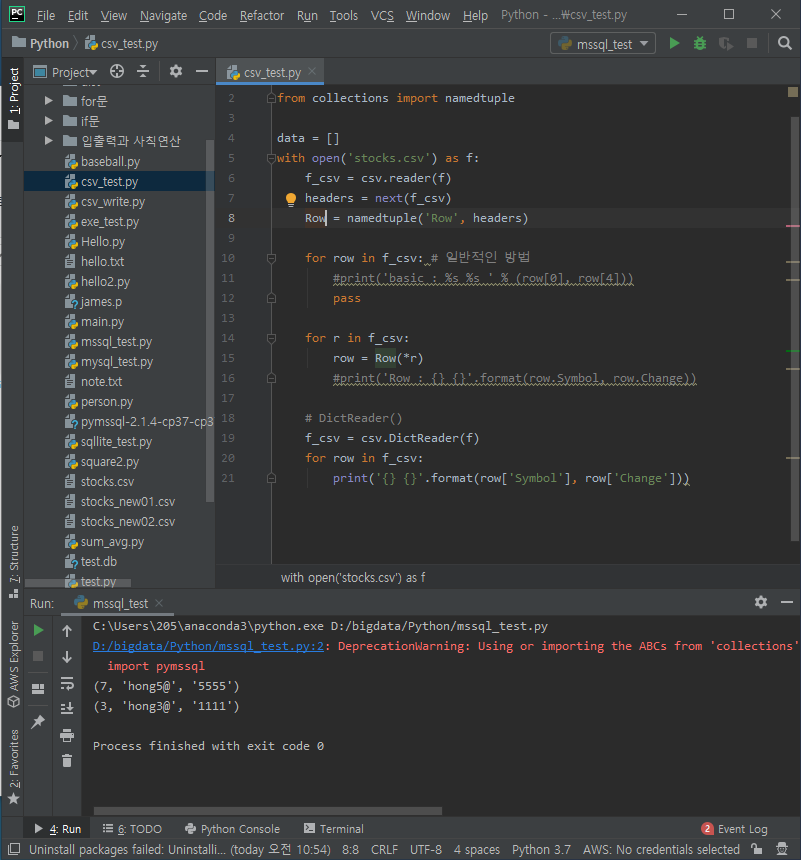
namedtuple 사용
import csv
from collections import namedtuple
with open('stocks.csv') as f:
f_csv = csv.reader(f)
headings = next(f_csv)
Row = namedtuple('Row', headings)
for r in f_csv:
row = Row(*r)
# Process row
#print(row)
print('Row : %s %s ' % (row.Symbol, row.Change))-
row.Symbol and row.Change
-
use of column headers
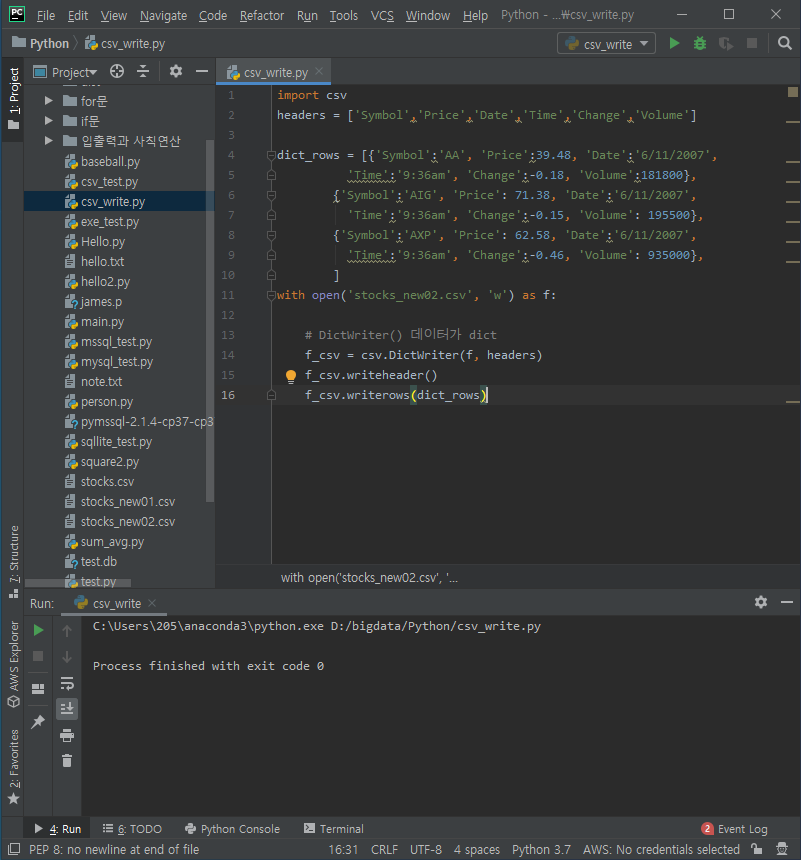
csv.DictReader 사용
import csv
with open('stocks.csv') as f:
f_csv = csv.DictReader(f)
for row in f_csv:
# process row
#print(row)
print('OrderedDict : %s %s ' % (row['Symbol'], row['Change']))-
row['Symbol'] or row['Change'].
쓰기(Writing)
csv.writer 사용

csv.DictWriter 사용