-
데이터 개념 예제로 이해하기R 2020. 7. 6. 15:22
데이터 개념 이해하기
예제로 이해하기
hflights 패키지 - 20만건 이상의 데이터
# 패키지 설치 install.packages('hflights')package 'hflights' successfully unpacked and MD5 sums checked The downloaded binary packages are in C:\Users\205\AppData\Local\Temp\RtmpwtIKSj\downloaded_packages# 공통 패키지 로드 library(ggplot2)Warning message: "package 'ggplot2' was built under R version 3.6.3"library(hflights)# 구조 살펴보기 - str() str(hflights)'data.frame': 227496 obs. of 21 variables: $ Year : int 2011 2011 2011 2011 2011 2011 2011 2011 2011 2011 ... $ Month : int 1 1 1 1 1 1 1 1 1 1 ... $ DayofMonth : int 1 2 3 4 5 6 7 8 9 10 ... $ DayOfWeek : int 6 7 1 2 3 4 5 6 7 1 ... $ DepTime : int 1400 1401 1352 1403 1405 1359 1359 1355 1443 1443 ... $ ArrTime : int 1500 1501 1502 1513 1507 1503 1509 1454 1554 1553 ... $ UniqueCarrier : chr "AA" "AA" "AA" "AA" ... $ FlightNum : int 428 428 428 428 428 428 428 428 428 428 ... $ TailNum : chr "N576AA" "N557AA" "N541AA" "N403AA" ... $ ActualElapsedTime: int 60 60 70 70 62 64 70 59 71 70 ... $ AirTime : int 40 45 48 39 44 45 43 40 41 45 ... $ ArrDelay : int -10 -9 -8 3 -3 -7 -1 -16 44 43 ... $ DepDelay : int 0 1 -8 3 5 -1 -1 -5 43 43 ... $ Origin : chr "IAH" "IAH" "IAH" "IAH" ... $ Dest : chr "DFW" "DFW" "DFW" "DFW" ... $ Distance : int 224 224 224 224 224 224 224 224 224 224 ... $ TaxiIn : int 7 6 5 9 9 6 12 7 8 6 ... $ TaxiOut : int 13 9 17 22 9 13 15 12 22 19 ... $ Cancelled : int 0 0 0 0 0 0 0 0 0 0 ... $ CancellationCode : chr "" "" "" "" ... $ Diverted : int 0 0 0 0 0 0 0 0 0 0 ...# 일부 확인 - head() head(hflights)Year Month DayofMonth DayOfWeek DepTime ArrTime UniqueCarrier FlightNum TailNum ActualElapsedTime ... ArrDelay DepDelay Origin Dest Distance TaxiIn TaxiOut Cancelled CancellationCode Diverted 5424 2011 1 1 6 1400 1500 AA 428 N576AA 60 ... -10 0 IAH DFW 224 7 13 0 0 5425 2011 1 2 7 1401 1501 AA 428 N557AA 60 ... -9 1 IAH DFW 224 6 9 0 0 5426 2011 1 3 1 1352 1502 AA 428 N541AA 70 ... -8 -8 IAH DFW 224 5 17 0 0 5427 2011 1 4 2 1403 1513 AA 428 N403AA 70 ... 3 3 IAH DFW 224 9 22 0 0 5428 2011 1 5 3 1405 1507 AA 428 N492AA 62 ... -3 5 IAH DFW 224 9 9 0 0 5429 2011 1 6 4 1359 1503 AA 428 N262AA 64 ... -7 -1 IAH DFW 224 6 13 0 0 # 특정 변수 확인 dest_table <- table(hflights$Dest) dest_tableABQ AEX AGS AMA ANC ASE ATL AUS AVL BFL BHM BKG BNA BOS BPT BRO 2812 724 1 1297 125 125 7886 5022 350 504 2736 110 3481 1752 3 1692 BTR BWI CAE CHS CID CLE CLT CMH COS CRP CRW CVG DAL DAY DCA DEN 1762 2551 561 1200 410 2140 4735 1348 1657 4813 357 1535 9820 451 2699 5920 DFW DSM DTW ECP EGE ELP EWR FLL GJT GPT GRK GRR GSO GSP GUC HDN 6653 647 2601 729 110 3036 4314 2462 403 1618 42 677 630 1123 86 110 HNL HOB HRL HSV IAD ICT IND JAN JAX JFK LAS LAX LBB LCH LEX LFT 402 309 3983 923 1980 1517 1750 2011 2135 695 4082 6064 1333 364 584 2313 LGA LIT LRD MAF MCI MCO MDW MEM MFE MIA MKE MLU MOB MSP MSY MTJ 2730 1579 1188 2306 3174 3687 2094 2399 1128 2463 1588 292 1674 2010 6823 164 OAK OKC OMA ONT ORD ORF PBI PDX PHL PHX PIT PNS PSP RDU RIC RNO 690 3170 2044 952 5748 717 1253 1235 2367 5096 1664 1539 106 1740 900 243 RSW SAN SAT SAV SDF SEA SFO SHV SJC SJU SLC SMF SNA STL TPA TUL 948 2936 4893 863 1279 2615 2818 787 885 391 2033 1014 1661 2509 3085 2924 TUS TYS VPS XNA 1565 1210 880 1172# 명목형 변수 개수 확인 - length() 벡터나 리스트등 개수 확인 함수 length(dest_table)116
# 범위 살펴보기 - range() 가장 큰값, 작은값 range(dest_table)- 1
- 9820
# 가장 큰값, 작은값의 이름 찾기 dest_table[dest_table == 1] # 오거스타 리저널 공항 dest_table[dest_table == 9820] # 댈러스 공항AGS: 1
DAL: 9820
# 5000 넘는 공항 dest_table_5000 <- dest_table[dest_table > 5000] dest_table_5000ATL AUS DAL DEN DFW LAX MSY ORD PHX 7886 5022 9820 5920 6653 6064 6823 5748 5096# 막대그리프 그리기 barplot(dest_table_5000)
막대그래프(barplot) 대장암 환자 자료 분석
-
보건의료 빅데이터 개방시스템 http://opendata.hira.or.kr
-
어느 연령대가 가장 많은 대장암이 발생하는 지 조사
# 데이터 로드 df <- read.csv('r-ggagi-data/example_cancer.csv')# 구조 파악 str(df)'data.frame': 18310 obs. of 8 variables: $ age : int 75 52 67 62 70 76 55 72 64 71 ... $ sex : Factor w/ 2 levels "남","여": 1 2 2 1 1 2 1 1 1 1 ... $ height : Factor w/ 485 levels "100","130","130.2",..: 252 408 182 262 352 352 467 165 172 232 ... $ weight : Factor w/ 638 levels "100","101","101.1",..: 333 446 349 263 343 563 463 243 363 248 ... $ dateOfoperation: Factor w/ 351 levels "2011-01-02","2011-01-03",..: 165 134 146 164 154 160 164 147 219 192 ... $ cancerStaging : Factor w/ 5 levels "I","II","III",..: 1 4 3 1 2 3 2 3 1 2 ... $ hospitalization: int 48 17 10 11 10 10 12 18 15 35 ... $ diseaseCode : Factor w/ 13 levels "C18","C180","C181",..: 9 9 9 9 4 11 9 4 13 11 ...head(df, 3)age sex height weight dateOfoperation cancerStaging hospitalization diseaseCode 75 남 161 64 2011-06-22 I 48 C187 52 여 176.6 75.3 2011-05-19 IV 17 C187 67 여 154 65.6 2011-05-31 III 10 C187 # 연령대별 도수 - 연속형 변수, 구간 나누기 (0~10], (10~20] ... age_table <- table(cut(df$age, breaks=(0:11)*10)) age_table(0,10] (10,20] (20,30] (30,40] (40,50] (50,60] (60,70] (70,80] 0 3 77 482 1917 4558 5679 4598 (80,90] (90,100] (100,110] 962 33 1rownames(age_table) <- c('1s','10s','20s','30s','40s','50s','60s','70s','80s','90s','100s') age_table1s 10s 20s 30s 40s 50s 60s 70s 80s 90s 100s 0 3 77 482 1917 4558 5679 4598 962 33 1# 시각화 1 barplot(age_table)
연령별 막대그래프 # 시각화 2 install.packages('ggthemes')package 'ggthemes' successfully unpacked and MD5 sums checked The downloaded binary packages are in C:\Users\205\AppData\Local\Temp\RtmpILoNVt\downloaded_packageslibrary('ggplot2') library('ggthemes')# aes 축 ggplot(data=df, aes(x=age)) + geom_freqpoly(binwidth=10, size=1.4, colour='orange') + theme_wsj()
theme_wsj의 경우 전국 커피숍 폐업 / 영업 상황 살펴 보기
-
공공데이터 포털 https://www.data.go.kr
# 데이터 로드 # read.csv의 옵션 default 값은 T df <- read.csv('r-ggagi-data/example_coffee.csv', header = T, stringsAsFactors = T)# 데이터 구조 파악 str(df)'data.frame': 46832 obs. of 23 variables: $ number : int 1 2 3 4 5 6 7 8 9 10 ... $ companyName : Factor w/ 36991 levels "-10","#11(Sharp eleven)",..: 2 4 5 6 7 8 9 10 11 12 ... $ adress : Factor w/ 45197 levels "","강원도 강릉시 강동면 안인진리 3-5번지 통일공원 G동 2층 ",..: 32695 45012 14332 25672 35262 44619 44059 16795 4038 16983 ... $ adressBystreet : Factor w/ 38866 levels "","강원도 강릉시 가작로 13, 1층 (교동)",..: 28058 38633 12180 22436 1 38386 37843 14490 3373 14482 ... $ dateOflicensing : int 20080917 20101124 20130902 20121108 20020911 20130822 20140605 20111209 20130315 20110908 ... $ stateOfbusiness : Factor w/ 2 levels "운영중","폐업 등": 1 1 1 1 2 1 1 1 1 1 ... $ dateOfclosure : int NA NA NA NA 20071105 NA NA NA NA NA ... $ startdateOfcessation: logi NA NA NA NA NA NA ... $ duedateOfcessation : logi NA NA NA NA NA NA ... $ dateOfreOpen : logi NA NA NA NA NA NA ... $ areaOfsite : logi NA NA NA NA NA NA ... $ zip : logi NA NA NA NA NA NA ... $ waterwork : Factor w/ 5 levels "","간이상수도",..: 4 4 4 4 4 4 4 4 4 4 ... $ numOfmenWorker : int NA NA NA NA 0 NA NA NA NA NA ... $ yearOfStart : int 2008 2010 2013 2012 2002 2013 2014 2011 2013 2011 ... $ multipleUse : Factor w/ 3 levels "","N","Y": 2 2 2 2 2 2 2 2 2 2 ... $ grade : Factor w/ 8 levels "","갑","관리",..: 1 1 1 1 1 1 1 1 1 1 ... $ sizeOfsite : num 20.8 212.7 20 64.2 11.4 ... $ numOfwomenWorker : int NA NA NA NA 0 NA NA NA NA NA ... $ vicintyOfsite : Factor w/ 8 levels "","결혼예식장주변",..: 1 1 4 1 1 1 1 3 1 3 ... $ sanitaryName : Factor w/ 2 levels "","휴게음식점": 2 2 2 2 2 2 2 2 2 2 ... $ businessCondition : Factor w/ 2 levels "","커피숍": 2 2 2 2 2 2 2 2 2 2 ... $ totalOfworker : int NA NA NA NA 0 NA NA NA NA NA ...# 불필요한 변수 제거 # 로우데이터를 같은 변수로 하면 수정 할 때 문제생김 (df2를 df2로 할 경우) df2 <- subset(df, select=c(-adressBystreet, -dateOfclosure, -startdateOfcessation, -duedateOfcessation, -dateOfreOpen, -zip)) str(df2)'data.frame': 46832 obs. of 17 variables: $ number : int 1 2 3 4 5 6 7 8 9 10 ... $ companyName : Factor w/ 36991 levels "-10","#11(Sharp eleven)",..: 2 4 5 6 7 8 9 10 11 12 ... $ adress : Factor w/ 45197 levels "","강원도 강릉시 강동면 안인진리 3-5번지 통일공원 G동 2층 ",..: 32695 45012 14332 25672 35262 44619 44059 16795 4038 16983 ... $ dateOflicensing : int 20080917 20101124 20130902 20121108 20020911 20130822 20140605 20111209 20130315 20110908 ... $ stateOfbusiness : Factor w/ 2 levels "운영중","폐업 등": 1 1 1 1 2 1 1 1 1 1 ... $ areaOfsite : logi NA NA NA NA NA NA ... $ waterwork : Factor w/ 5 levels "","간이상수도",..: 4 4 4 4 4 4 4 4 4 4 ... $ numOfmenWorker : int NA NA NA NA 0 NA NA NA NA NA ... $ yearOfStart : int 2008 2010 2013 2012 2002 2013 2014 2011 2013 2011 ... $ multipleUse : Factor w/ 3 levels "","N","Y": 2 2 2 2 2 2 2 2 2 2 ... $ grade : Factor w/ 8 levels "","갑","관리",..: 1 1 1 1 1 1 1 1 1 1 ... $ sizeOfsite : num 20.8 212.7 20 64.2 11.4 ... $ numOfwomenWorker : int NA NA NA NA 0 NA NA NA NA NA ... $ vicintyOfsite : Factor w/ 8 levels "","결혼예식장주변",..: 1 1 4 1 1 1 1 3 1 3 ... $ sanitaryName : Factor w/ 2 levels "","휴게음식점": 2 2 2 2 2 2 2 2 2 2 ... $ businessCondition: Factor w/ 2 levels "","커피숍": 2 2 2 2 2 2 2 2 2 2 ... $ totalOfworker : int NA NA NA NA 0 NA NA NA NA NA ...# 최초 커피숍 찾기 range(df2$yearOfStart) # 결측치를 제거해야 출력됨 range(df2$yearOfStart, na.rm=T) # 결측치 제거 subset(df2, subset = (yearOfStart == 1964))- <NA>
- <NA>
- 1964
- 2015
number companyName adress dateOflicensing stateOfbusiness areaOfsite waterwork numOfmenWorker yearOfStart multipleUse grade sizeOfsite numOfwomenWorker vicintyOfsite sanitaryName businessCondition totalOfworker 23035 23035 엠에스커피 경기도 수원시 팔달구 매산로1가 16-5번지 19641125 폐업 등 NA 상수도전용 0 1964 N 0 0 기타 휴게음식점 커피숍 0 46290 46290 홀릭 부산광역시 중구 남포동4가 4-4번지 (2층) 19640929 폐업 등 NA 0 1964 N 기타 0 0 기타 휴게음식점 커피숍 0 # 가장 오래된 운영중인 커피숍 찾기 df_filter <- subset(df2, subset = (stateOfbusiness == '운영중')) range(df_filter$yearOfStart, na.rm = T) # 결측치 제거 subset(df_filter, subset = (yearOfStart == 1967))- 1967
- 2015
number companyName adress dateOflicensing stateOfbusiness areaOfsite waterwork numOfmenWorker yearOfStart multipleUse grade sizeOfsite numOfwomenWorker vicintyOfsite sanitaryName businessCondition totalOfworker 24108 24108 왕관 커피숍 서울특별시 종로구 종로5가 182-3번지 (1층) 19671013 운영중 NA 상수도전용 0 1967 N 갑 76.02 1 기타 휴게음식점 커피숍 1 44934 44934 학커피숍 인천광역시 중구 경동 219번지 19670414 운영중 NA 0 1967 N 59.13 0 휴게음식점 커피숍 0 head(subset(df_filter, subset = (yearOfStart == 2015)))number companyName adress dateOflicensing stateOfbusiness areaOfsite waterwork numOfmenWorker yearOfStart multipleUse grade sizeOfsite numOfwomenWorker vicintyOfsite sanitaryName businessCondition totalOfworker 22 22 (재)케이티그룹희망나눔재단 신사점(위드미) 서울특별시 강남구 신사동 603번지 20150526 운영중 NA NA 2015 N 173.51 NA 휴게음식점 커피숍 NA 25 25 (주) 리투스코리아 서울특별시 종로구 청운동 108-21번지 20150513 운영중 NA NA 2015 N 16.50 NA 휴게음식점 커피숍 NA 30 30 (주) 휴먼푸드 보다카페 인천광역시 연수구 송도동 30-3번지 30-3외 1필지 A동 4-1호 20150408 운영중 NA NA 2015 N 16.10 NA 휴게음식점 커피숍 NA 72 72 (주)나이스커피시스템 압구정점 서울특별시 강남구 압구정동 426번지 20150423 운영중 NA NA 2015 N 32.11 NA 휴게음식점 커피숍 NA 125 125 (주)동원홈푸드 다정다감카페 울산광역시 남구 옥동 1415번지 20150521 운영중 NA 상수도전용 NA 2015 N 54.99 NA 휴게음식점 커피숍 NA 133 133 (주)동원홈푸드 한국고용정보원점 충청북도 음성군 맹동면 두성리 175번지 20150206 운영중 NA NA 2015 N 9.00 NA 휴게음식점 커피숍 NA tail(subset(df_filter, subset = (yearOfStart == 2015)))number companyName adress dateOflicensing stateOfbusiness areaOfsite waterwork numOfmenWorker yearOfStart multipleUse grade sizeOfsite numOfwomenWorker vicintyOfsite sanitaryName businessCondition totalOfworker 46710 46710 희희 경기도 오산시 원동 774-10번지 1층 20150311 운영중 NA 상수도전용 NA 2015 N 26.16 NA 휴게음식점 커피숍 NA 46745 46745 히카리커피숍 전라북도 전주시 완산구 삼천동1가 640-10번지 20150106 운영중 NA 상수도전용 NA 2015 N 32.34 NA 휴게음식점 커피숍 NA 46785 46785 힐링카페 경기도 시흥시 신천동 733번지 4층 20150407 운영중 NA NA 2015 N 0.00 NA 휴게음식점 커피숍 NA 46795 46795 힐링카페숨 충청북도 청주시 상당구 북문로3가 99-7번지 2층 20150430 운영중 NA 상수도전용 NA 2015 N 94.16 NA 휴게음식점 커피숍 NA 46824 46824 힐하우스커피 강원도 동해시 어달동 45번지 1층 20150429 운영중 NA 상수도전용 NA 2015 N 42.04 NA 기타 휴게음식점 커피숍 NA 46826 46826 茶우림 전라남도 담양군 수북면 궁산리 389-4번지 20150429 운영중 NA 상수도전용 NA 2015 N 128.50 NA 기타 휴게음식점 커피숍 NA # 해마다 오픈하는 커피숍 개수 찾기 table(df2$yearOfStart)1964 1966 1967 1968 1969 1970 1971 1972 1974 1975 1976 1979 1980 1981 1982 1983 2 2 3 1 2 4 6 3 1 2 5 4 9 8 12 9 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 11 18 21 21 26 23 25 28 37 50 48 48 41 54 54 46 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 89 183 398 799 648 654 863 1233 1579 2489 4172 5942 6315 7270 9905 3650# 시각화 1 qplot(data=df2, yearOfStart, geom='bar') # 2000년부터 성장, 2010년부터 급성장 # 1999년 스타벅스 1호점 입점Warning message: "Removed 19 rows containing non-finite values (stat_count)."
해마다 오픈하는 커피숍 갯수 # 분할표 작성 - 운영중 / 폐업 stat_table <- table(df2$stateOfbusiness, df2$yearOfStart) stat_table1964 1966 1967 1968 1969 1970 1971 1972 1974 1975 1976 1979 1980 1981 운영중 0 0 2 0 0 2 4 2 1 1 1 2 3 6 폐업 등 2 2 1 1 2 2 2 1 0 1 4 2 6 2 1982 1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 운영중 2 3 4 5 5 6 11 5 7 7 3 14 14 13 폐업 등 10 6 7 13 16 15 15 18 18 21 34 36 34 35 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009 운영중 14 21 25 23 26 76 105 163 180 204 314 496 729 1229 폐업 등 27 33 29 23 63 107 293 636 468 450 549 737 850 1260 2010 2011 2012 2013 2014 2015 운영중 2503 3961 4642 6045 9125 3564 폐업 등 1669 1981 1673 1225 780 86# 조건으로 특정 컬럼값 찾기 - which(), rownames 열조건 colnames # 조건이 TRUE일 때만 찾아줌 # colnames(stat_table) == 1993 which(colnames(stat_table) == 1993) which.max(colnames(stat_table))26
48
# 원하는 컬럼으로 분할 stat_table_26_93 <- stat_table[,c(26:48)] stat_table_26_931993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 운영중 14 14 13 14 21 25 23 26 76 105 163 180 204 314 폐업 등 36 34 35 27 33 29 23 63 107 293 636 468 450 549 2007 2008 2009 2010 2011 2012 2013 2014 2015 운영중 496 729 1229 2503 3961 4642 6045 9125 3564 폐업 등 737 850 1260 1669 1981 1673 1225 780 86# 비율 계산 stat_prop_table <- prop.table(stat_table_26_93, margin = 2) # margin = 2 열 기준 stat_prop_table1993 1994 1995 1996 1997 1998 운영중 0.28000000 0.29166667 0.27083333 0.34146341 0.38888889 0.46296296 폐업 등 0.72000000 0.70833333 0.72916667 0.65853659 0.61111111 0.53703704 1999 2000 2001 2002 2003 2004 운영중 0.50000000 0.29213483 0.41530055 0.26381910 0.20400501 0.27777778 폐업 등 0.50000000 0.70786517 0.58469945 0.73618090 0.79599499 0.72222222 2005 2006 2007 2008 2009 2010 운영중 0.31192661 0.36384705 0.40227088 0.46168461 0.49377260 0.59995206 폐업 등 0.68807339 0.63615295 0.59772912 0.53831539 0.50622740 0.40004794 2011 2012 2013 2014 2015 운영중 0.66661057 0.73507522 0.83149931 0.92125189 0.97643836 폐업 등 0.33338943 0.26492478 0.16850069 0.07874811 0.02356164# 데이터 프레임 구성 input1 <- stat_table_26_93 input2 <- stat_prop_table # df_bind <- data.frame(colnames(input1)) # df_bind <- data.frame(colnames(input1),input1[1,]) # df_bind <- data.frame(colnames(input1),input1[1,],input1[2,]) # df_bind <- data.frame(colnames(input1),input1[1,],input1[2,],input2[1,]) df_bind <- data.frame(colnames(input1),input1[1,],input1[2,],input2[1,],input2[2,]) df_bindcolnames.input1. input1.1... input1.2... input2.1... input2.2... 1993 1993 14 36 0.2800000 0.72000000 1994 1994 14 34 0.2916667 0.70833333 1995 1995 13 35 0.2708333 0.72916667 1996 1996 14 27 0.3414634 0.65853659 1997 1997 21 33 0.3888889 0.61111111 1998 1998 25 29 0.4629630 0.53703704 1999 1999 23 23 0.5000000 0.50000000 2000 2000 26 63 0.2921348 0.70786517 2001 2001 76 107 0.4153005 0.58469945 2002 2002 105 293 0.2638191 0.73618090 2003 2003 163 636 0.2040050 0.79599499 2004 2004 180 468 0.2777778 0.72222222 2005 2005 204 450 0.3119266 0.68807339 2006 2006 314 549 0.3638470 0.63615295 2007 2007 496 737 0.4022709 0.59772912 2008 2008 729 850 0.4616846 0.53831539 2009 2009 1229 1260 0.4937726 0.50622740 2010 2010 2503 1669 0.5999521 0.40004794 2011 2011 3961 1981 0.6666106 0.33338943 2012 2012 4642 1673 0.7350752 0.26492478 2013 2013 6045 1225 0.8314993 0.16850069 2014 2014 9125 780 0.9212519 0.07874811 2015 2015 3564 86 0.9764384 0.02356164 # 행, 열 이름 정리 # 행이름 삭제 rownames(df_bind) <- NULL colnames(df_bind) <- c('Year', 'Open', 'Close', 'POpen', 'PClose') df_bindYear Open Close POpen PClose 1993 14 36 0.2800000 0.72000000 1994 14 34 0.2916667 0.70833333 1995 13 35 0.2708333 0.72916667 1996 14 27 0.3414634 0.65853659 1997 21 33 0.3888889 0.61111111 1998 25 29 0.4629630 0.53703704 1999 23 23 0.5000000 0.50000000 2000 26 63 0.2921348 0.70786517 2001 76 107 0.4153005 0.58469945 2002 105 293 0.2638191 0.73618090 2003 163 636 0.2040050 0.79599499 2004 180 468 0.2777778 0.72222222 2005 204 450 0.3119266 0.68807339 2006 314 549 0.3638470 0.63615295 2007 496 737 0.4022709 0.59772912 2008 729 850 0.4616846 0.53831539 2009 1229 1260 0.4937726 0.50622740 2010 2503 1669 0.5999521 0.40004794 2011 3961 1981 0.6666106 0.33338943 2012 4642 1673 0.7350752 0.26492478 2013 6045 1225 0.8314993 0.16850069 2014 9125 780 0.9212519 0.07874811 2015 3564 86 0.9764384 0.02356164 # 시각화 - linie graph ggplot(df_bind, aes(x=Year, y=Close, group=1)) + geom_line(colour='steelblue1', size=1) + geom_point(colour='steelblue', size=3) + geom_line(aes(y=Open), colour='tomato2', size=1) + geom_point(aes(y=Open), colour='red', size=3) + theme_bw()
운영 / 폐업 그래프 전국 커피숍 규모 파악하기
head(df)number companyName adress adressBystreet dateOflicensing stateOfbusiness dateOfclosure startdateOfcessation duedateOfcessation dateOfreOpen ... numOfmenWorker yearOfStart multipleUse grade sizeOfsite numOfwomenWorker vicintyOfsite sanitaryName businessCondition totalOfworker 1 #11(Sharp eleven) 서울특별시 양천구 목동 956번지 롯데캐슬위너 상가동 107호(한두3길 44) 서울특별시 양천구 목동중앙북로 38 (목동,롯데캐슬위너 상가동 107호(한두3길 44)) 20080917 운영중 NA NA NA NA ... NA 2008 N 20.80 NA 휴게음식점 커피숍 NA 2 ( 주)커피빈코리아청주지웰시티점 충청북도 청주시 흥덕구 복대동 3379번지 신영지웰시티1차상업시설 124-1, 125, 126호(1층) 충청북도 청주시 흥덕구 대농로 17 (복대동,신영지웰시티1차상업시설 124-1, 125, 126호(1층)) 20101124 운영중 NA NA NA NA ... NA 2010 N 212.72 NA 휴게음식점 커피숍 NA 3 (aA)더블에이 경상북도 경산시 사동 39번지 108-2호 경상북도 경산시 백자로10길 3-11, 108-2호 (사동) 20130902 운영중 NA NA NA NA ... NA 2013 N 20.04 NA 아파트지역 휴게음식점 커피숍 NA 4 (강서)카페치따 서울특별시 강서구 등촌동 63-12번지 외 2필지 어위쉬예다인 (지상 1층) 104호 서울특별시 강서구 양천로 452, 1층 104호 (등촌동, 3동 어위쉬예다인) 20121108 운영중 NA NA NA NA ... NA 2012 N 64.17 NA 휴게음식점 커피숍 NA 5 (로즈버드)명동아바타 서울특별시 중구 명동2가 83-5번지 (아바타1층1218) 20020911 폐업 등 20071105 NA NA NA ... 0 2002 N 11.40 0 휴게음식점 커피숍 0 6 (루앤비카페(Lu n B cafe) 충청북도 청주시 서원구 사직동 720-31번지 외7필지 (1층) 충청북도 청주시 서원구 사직대로 246 (사직동, (1층)) 20130822 운영중 NA NA NA NA ... NA 2013 N 10.99 NA 휴게음식점 커피숍 NA # 규모 데이터 별도 저장 size <- df$sizeOfsite# 자료 특성 파악 str, summary 많이사용 # summary() 기본 통계값 보여줌 summary(size)Min. 1st Qu. Median Mean 3rd Qu. Max. NA's 0.00 28.12 50.00 75.53 93.75 24075.00 19# 아웃라이어(이상치) 삭제 - 평균보다 지나치게 다른 값 size[size > 10000] <- NA size[size == 0] <- NA# 결측치 제거(NA 값 제거) - complete.cases() NA 값 false리턴 size <- size[complete.cases(size)]summary(size)Min. 1st Qu. Median Mean 3rd Qu. Max. 0.25 30.00 51.92 77.23 95.30 1406.38# 20단위 계급 생성 degree_size <- table(cut(size, breaks=(0:72)*20)) degree_size(0,20] (20,40] (40,60] (60,80] 6026 11303 8293 5283 (80,100] (100,120] (120,140] (140,160] 4239 2246 1751 1297 (160,180] (180,200] (200,220] (220,240] 959 882 568 512 (240,260] (260,280] (280,300] (300,320] 394 331 347 179 (320,340] (340,360] (360,380] (380,400] 191 112 105 94 (400,420] (420,440] (440,460] (460,480] 81 60 42 34 (480,500] (500,520] (520,540] (540,560] 32 18 16 14 (560,580] (580,600] (600,620] (620,640] 12 9 9 5 (640,660] (660,680] (680,700] (700,720] 4 4 0 1 (720,740] (740,760] (760,780] (780,800] 1 2 4 1 (800,820] (820,840] (840,860] (860,880] 1 1 0 0 (880,900] (900,920] (920,940] (940,960] 0 2 1 0 (960,980] (980,1e+03] (1e+03,1.02e+03] (1.02e+03,1.04e+03] 0 1 0 0 (1.04e+03,1.06e+03] (1.06e+03,1.08e+03] (1.08e+03,1.1e+03] (1.1e+03,1.12e+03] 2 0 0 0 (1.12e+03,1.14e+03] (1.14e+03,1.16e+03] (1.16e+03,1.18e+03] (1.18e+03,1.2e+03] 0 0 0 0 (1.2e+03,1.22e+03] (1.22e+03,1.24e+03] (1.24e+03,1.26e+03] (1.26e+03,1.28e+03] 1 0 0 0 (1.28e+03,1.3e+03] (1.3e+03,1.32e+03] (1.32e+03,1.34e+03] (1.34e+03,1.36e+03] 0 0 0 0 (1.36e+03,1.38e+03] (1.38e+03,1.4e+03] (1.4e+03,1.42e+03] (1.42e+03,1.44e+03] 0 0 1 0# 시각화 - 30~40 (10평) 제일 많음 ggplot(data=df, aes(x=sizeOfsite)) + geom_freqpoly(binwidth=10, size=1.2, colour='orange') + scale_x_continuous(limits=c(0,300), breaks=seq(0, 300, 20)) + theme_wsj()Warning message: "Removed 1060 rows containing non-finite values (stat_bin)."Warning message: "Removed 2 row(s) containing missing values (geom_path)."
커피숍 규모 그래프 전국 인구조사 자료 정리하기
-
통계청 작성 전국 인구조사 데이터
-
시별 도별 인구수
-
인구수에 ',' 가 있어 문자열로 불러오기 stringsAsFactors = F
# Data 불러오기 df <- read.csv('r-ggagi-data/example_population.csv', stringsAsFactors = F)# 자료 살펴보기 str(df)'data.frame': 281 obs. of 7 variables: $ City : chr "서울특별시 (1100000000)" "서울특별시 종로구 (1111000000)" "서울특별시 중구 (1114000000)" "서울특별시 용산구 (1117000000)" ... $ Population: chr "10,078,850" "155,695" "126,817" "235,186" ... $ Households: chr "4,197,478" "72,882" "59,614" "108,138" ... $ PersInHou : num 2.4 2.14 2.13 2.17 2.35 2.28 2.26 2.36 2.41 2.36 ... $ Male : chr "4,962,774" "76,962" "63,292" "114,119" ... $ Female : chr "5,116,076" "78,733" "63,525" "121,067" ... $ SexRatio : num 0.97 0.98 1 0.94 0.99 0.97 1.01 1 0.96 0.97 ...# 자료 값 확인 head() head(df)City Population Households PersInHou Male Female SexRatio 서울특별시 (1100000000) 10,078,850 4,197,478 2.40 4,962,774 5,116,076 0.97 서울특별시 종로구 (1111000000) 155,695 72,882 2.14 76,962 78,733 0.98 서울특별시 중구 (1114000000) 126,817 59,614 2.13 63,292 63,525 1.00 서울특별시 용산구 (1117000000) 235,186 108,138 2.17 114,119 121,067 0.94 서울특별시 성동구 (1120000000) 298,145 126,915 2.35 148,265 149,880 0.99 서울특별시 광진구 (1121500000) 362,197 158,769 2.28 177,946 184,251 0.97 # 서울특별시 종로구 (1111000000) => 서울특별시 종로구 이렇게 만들기 # 문자열 분리 - str_split_fixed() install.packages('stringr')package 'stringr' successfully unpacked and MD5 sums checked The downloaded binary packages are in C:\Users\205\AppData\Local\Temp\RtmpILoNVt\downloaded_packageslibrary('stringr')# ( 기준으로 2개 분리 temp <- str_split_fixed(df[,1], '\\(', 2) head(temp)서울특별시 1100000000) 서울특별시 종로구 1111000000) 서울특별시 중구 1114000000) 서울특별시 용산구 1117000000) 서울특별시 성동구 1120000000) 서울특별시 광진구 1121500000) # 공백 기준으로 시 구 분리 => 분리해야 더 다양한 분석 가능 new_city <- str_split_fixed(temp[,1], ' ', 2) head(new_city)서울특별시 서울특별시 종로구 서울특별시 중구 서울특별시 용산구 서울특별시 성동구 서울특별시 광진구 # 변수명 변경 colnames(new_city) <- c('Provinces', 'City') head(new_city)Provinces City 서울특별시 서울특별시 종로구 서울특별시 중구 서울특별시 용산구 서울특별시 성동구 서울특별시 광진구 # 새로운 dataframe 생성 df_new <- data.frame(new_city, df[,c(2:7)]) df_new[df_new$Provinces == '세종특별자치시',]Provinces City Population Households PersInHou Male Female SexRatio 82 세종특별자치시 185,212 72,733 2.55 93,058 92,154 1.01 83 세종특별자치시 185,212 72,733 2.55 93,058 92,154 1.01 # City 공백 => NA df_new[df_new == ' '] <- NA head(df_new) df_new[df_new$Provinces == '세종특별자치시',]Provinces City Population Households PersInHou Male Female SexRatio 서울특별시 NA 10,078,850 4,197,478 2.40 4,962,774 5,116,076 0.97 서울특별시 종로구 155,695 72,882 2.14 76,962 78,733 0.98 서울특별시 중구 126,817 59,614 2.13 63,292 63,525 1.00 서울특별시 용산구 235,186 108,138 2.17 114,119 121,067 0.94 서울특별시 성동구 298,145 126,915 2.35 148,265 149,880 0.99 서울특별시 광진구 362,197 158,769 2.28 177,946 184,251 0.97 Provinces City Population Households PersInHou Male Female SexRatio 82 세종특별자치시 NA 185,212 72,733 2.55 93,058 92,154 1.01 83 세종특별자치시 NA 185,212 72,733 2.55 93,058 92,154 1.01 # NA 행 삭제 - complete.cases() NA 가 있는 행 FALSE df_new2 <- df_new[complete.cases(df_new),] head(df_new2) df_new2[df_new2$Provinces == '세종특별자치시',]Provinces City Population Households PersInHou Male Female SexRatio 2 서울특별시 종로구 155,695 72,882 2.14 76,962 78,733 0.98 3 서울특별시 중구 126,817 59,614 2.13 63,292 63,525 1.00 4 서울특별시 용산구 235,186 108,138 2.17 114,119 121,067 0.94 5 서울특별시 성동구 298,145 126,915 2.35 148,265 149,880 0.99 6 서울특별시 광진구 362,197 158,769 2.28 177,946 184,251 0.97 7 서울특별시 동대문구 362,604 160,110 2.26 181,825 180,779 1.01 Provinces City Population Households PersInHou Male Female SexRatio head(complete.cases(df_new))- FALSE
- TRUE
- TRUE
- TRUE
- TRUE
- TRUE
# is.na() NA 가 있는 값 TRUE head(is.na(df_new))Provinces City Population Households PersInHou Male Female SexRatio FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE # NA 가 있는 행 불러오기 df_new3 <- df_new[is.na(df_new$City),] df_new3Provinces City Population Households PersInHou Male Female SexRatio 1 서울특별시 NA 10,078,850 4,197,478 2.40 4,962,774 5,116,076 0.97 27 부산광역시 NA 3,517,491 1,430,441 2.46 1,737,975 1,779,516 0.98 44 대구광역시 NA 2,491,137 977,714 2.55 1,239,275 1,251,862 0.99 53 인천광역시 NA 2,914,271 1,145,232 2.54 1,464,320 1,449,951 1.01 64 광주광역시 NA 1,476,974 577,941 2.56 731,808 745,166 0.98 70 대전광역시 NA 1,525,656 595,216 2.56 763,262 762,394 1.00 76 울산광역시 NA 1,169,768 447,229 2.62 602,945 566,823 1.06 82 세종특별자치시 NA 185,212 72,733 2.55 93,058 92,154 1.01 83 세종특별자치시 NA 185,212 72,733 2.55 93,058 92,154 1.01 84 경기도 NA 12,432,063 4,829,521 2.57 6,256,986 6,175,077 1.01 136 강원도 NA 1,547,166 680,373 2.27 780,487 766,679 1.02 155 충청북도 NA 1,582,181 664,186 2.38 797,908 784,273 1.02 171 충청남도 NA 2,068,444 878,544 2.35 1,049,546 1,018,898 1.03 189 전라북도 NA 1,869,668 778,350 2.40 930,224 939,444 0.99 206 전라남도 NA 1,902,638 827,264 2.30 950,693 951,945 1.00 229 경상북도 NA 2,697,791 1,160,150 2.33 1,354,618 1,343,173 1.01 255 경상남도 NA 3,356,540 1,356,430 2.47 1,690,798 1,665,742 1.02 279 제주특별자치도 NA 615,250 251,478 2.45 308,627 306,623 1.01 df_new4 <- df_new[!complete.cases(df_new),] head(df_new4)Provinces City Population Households PersInHou Male Female SexRatio 1 서울특별시 NA 10,078,850 4,197,478 2.40 4,962,774 5,116,076 0.97 27 부산광역시 NA 3,517,491 1,430,441 2.46 1,737,975 1,779,516 0.98 44 대구광역시 NA 2,491,137 977,714 2.55 1,239,275 1,251,862 0.99 53 인천광역시 NA 2,914,271 1,145,232 2.54 1,464,320 1,449,951 1.01 64 광주광역시 NA 1,476,974 577,941 2.56 731,808 745,166 0.98 70 대전광역시 NA 1,525,656 595,216 2.56 763,262 762,394 1.00 # 인구수 변수 ' , ' 처리하고 수치형으로 변환 str(df_new2)'data.frame': 263 obs. of 8 variables: $ Provinces : Factor w/ 17 levels "강원도","경기도",..: 9 9 9 9 9 9 9 9 9 9 ... $ City : Factor w/ 241 levels " ","가평군 ",..: 188 189 158 105 32 65 190 106 6 63 ... $ Population: chr "155,695" "126,817" "235,186" "298,145" ... $ Households: chr "72,882" "59,614" "108,138" "126,915" ... $ PersInHou : num 2.14 2.13 2.17 2.35 2.28 2.26 2.36 2.41 2.36 2.57 ... $ Male : chr "76,962" "63,292" "114,119" "148,265" ... $ Female : chr "78,733" "63,525" "121,067" "149,880" ... $ SexRatio : num 0.98 1 0.94 0.99 0.97 1.01 1 0.96 0.97 0.97 ...for(i in 3:8){ df_new2[, i] <- sapply(df_new2[, i], function(x) gsub(',','',x)) df_new2[, i] <- as.numeric(df_new2[, i]) } df_fin <- df_new2head(df_fin)Provinces City Population Households PersInHou Male Female SexRatio 2 서울특별시 종로구 155695 72882 2.14 76962 78733 0.98 3 서울특별시 중구 126817 59614 2.13 63292 63525 1.00 4 서울특별시 용산구 235186 108138 2.17 114119 121067 0.94 5 서울특별시 성동구 298145 126915 2.35 148265 149880 0.99 6 서울특별시 광진구 362197 158769 2.28 177946 184251 0.97 7 서울특별시 동대문구 362604 160110 2.26 181825 180779 1.01 # 그룹별로 동일한 함수 적용 - tapply(적용할 변수, 그룹지을 변수, 적용할 변수) # tapply(heigh, sex, mean) - 성별로 키 값 평균 # 도(첫번째 변수)별 인구수 합계 sum_pop <- tapply(df_fin$Population, df_fin$Provinces, sum) sum_pop- 강원도
- 1547166
- 경기도
- 18723822
- 경상남도
- 4428762
- 경상북도
- 3215695
- 광주광역시
- 1476974
- 대구광역시
- 2491137
- 대전광역시
- 1525656
- 부산광역시
- 3517491
- 서울특별시
- 10078850
- 세종특별자치시
- <NA>
- 울산광역시
- 1169768
- 인천광역시
- 2914271
- 전라남도
- 1902638
- 전라북도
- 2523806
- 제주특별자치도
- 615250
- 충청남도
- 2671383
- 충청북도
- 2414568
# Level 값이 남아있어 나온 세종특별자치시 삭제 df_fin[, 1] <- factor(df_fin[, 1]) #값이 없는 level 삭제됨 sum_pop <- tapply(df_fin$Population, df_fin$Provinces, sum) sum_pop- 강원도
- 1547166
- 경기도
- 18723822
- 경상남도
- 4428762
- 경상북도
- 3215695
- 광주광역시
- 1476974
- 대구광역시
- 2491137
- 대전광역시
- 1525656
- 부산광역시
- 3517491
- 서울특별시
- 10078850
- 울산광역시
- 1169768
- 인천광역시
- 2914271
- 전라남도
- 1902638
- 전라북도
- 2523806
- 제주특별자치도
- 615250
- 충청남도
- 2671383
- 충청북도
- 2414568
# 시각화 - ggplot() library('ggplot2') library('ggthemes')ggplot(df_fin, aes(x=Provinces, y=Population, fill=Provinces)) + geom_bar(stat='identity') + theme_wsj()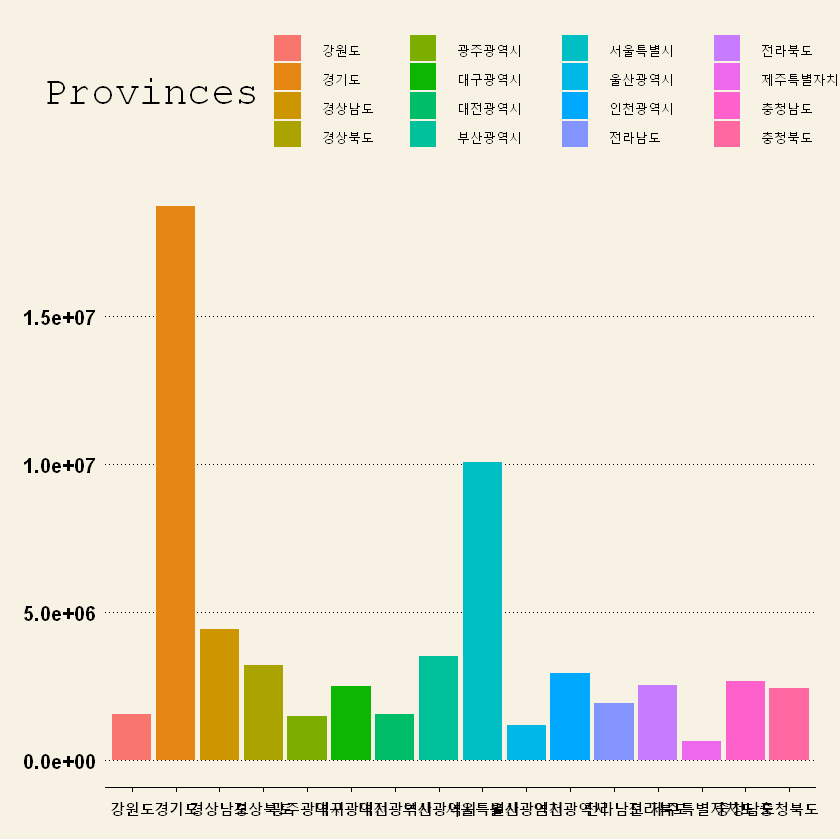
# csv로 저장하기 write.csv(df_fin, 'example_population_f.csv')'R' 카테고리의 다른 글
기술통계 - 실전 예제 (0) 2020.07.07 기술통계 (0) 2020.07.06 데이터 개념 이해하기 (0) 2020.07.02 R 필수 설치 패키지 (0) 2020.07.02 Python 가상환경 생성 및 R 주피터 노트북 연결 (0) 2020.07.02