-
데이터 개념 이해하기R 2020. 7. 2. 15:44
데이터 개념 이해하기
통계로 개념 이해하기
표로 데이터 정리하기
-
통계에서 데이터를 다루는 것은 데이터를 '표'로 잘 정리하고 나타내는 것
데이터의 종류
-
데이터의 종류에 따라 데이터 분석 방법이 다름!
수치형 데이터
-
이산형 데이터 : 독립적인 값, 정수 > 이항 분포를 따르는 확률질량함수
-
연속형 데이터 : 연속적인 값, 실수 > 확률밀도함수
범주형 데이터
-
명목형 데이터 : 순서 없는 문자 > 남,여
-
순서형 데이터 : 순서 있는 문자 > 학점(A~F)
데이터 손질하기
-
데이터를 표로 잘 정리하는 것은 통계 전체 작업에서 50%이상을 완성 했다는 의미
명목형 변수 - 도수분포표
-
도수 : 거듭하는 횟수
-
측정한 값의 빈도수를 정리한 표
명목형 변수 - 상대도수분포표
-
상대도수 : 변수값이 전체 변수값에서 어떤 비중을 차지하는 지 나타 내는 것
-
상대도수를 표료 만든 것
연속형 변수 - 도수분포표
-
연속형 변수는 구간(계급)을 정해 구간 안의 수를 세어 표시
-
구간의 범위는 데이터에 따라 정함
누적상대도수분포표
-
상대도수를 더해가며 누적된 값을 나타낸 값
ex) example_studentlist2.csv 파일로 도수분표표, 상대도수분포표, 누적상대도수분포표를 만들어 보세요.
분할표
-
두 가지 변수를 표로 정리한 것
데이터프레임
-
표를 R에서 다룰 때 "데이터프레임"이라는 특별한 객체에 담아서 사용
벡터 - R의 최소 데이터 단위
-
character
-
factor : 순서형, 명목형 변수
-
integer: 이산형 변수
-
numeric: 연속형 변수
ex) 벡터 만들기
a1 <- c(1,2,3,4,5) a1is(a1)a2 <- c(1L,2L,3L) a2is(a2)a3 <- as.integer(a1) a3is(a3)
벡터 만들기 1 b <- c(1.23, 3.14, 6.66) bc1 <- c('a','b','b','c','a') c1is(c)c2 <- c(1,2,3,'a') c2is(c2)d1 <- as.factor(c1) d1
벡터 만들기 2 is(d1)d2 <- factor(d1, levels = c('a','b','c','d')) d2
ex) dagaframe 만들기
a1 <- c(1,2,3,4,5) b1 <- c('a','b','c','d','e') c1 <- c(1.1, 2.2, 3.3, 4.4, 5.5)df1 <- data.frame(a1, b1, c1) df1
벡터, 데이터 프레임 만들기 df2 <- data.frame(count=a1, name=b1, meanCount=c1) df2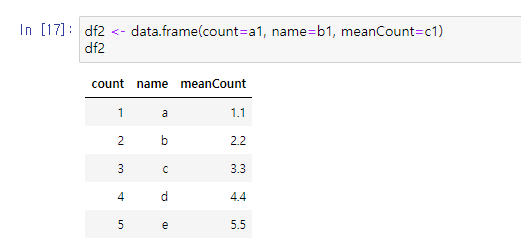
데이터 프레임 만들기2
ex) 외부 데이터 가져오기
# csv 파일 불러 오기 df_csv <- read.csv('r-ggagi-data/example_studentlist.csv')df_csvname sex age grade absence bloodtype height weight 김길동 남자 23 3 유 O 165.3 68.2 이미린 여자 22 2 무 AB 170.1 53.0 홍길동 남자 24 4 무 B 175.0 80.1 김철수 남자 23 3 무 AB 182.1 85.7 손세수 여자 20 1 유 A 168.0 49.5 박미희 여자 21 2 무 O 162.0 52.0 강수친 여자 22 1 무 O 155.2 45.3 이희수 여자 23 1 무 A 176.9 55.0 이철린 남자 23 3 무 B 178.5 64.2 방희철 남자 22 2 무 B 176.1 61.3 박수호 남자 24 4 유 O 167.1 62.0 임동민 남자 22 2 무 AB 180.0 75.8 김민수 남자 21 1 무 A 162.2 55.3 이희진 여자 23 3 무 O 176.1 53.1 김미진 여자 22 2 무 B 158.2 45.2 김동수 남자 24 4 유 B 168.6 70.2 여수근 남자 21 1 무 A 169.2 62.2 # 벡터 확인 is.vector(df_csv$height)TRUE
# 데이프레임 구조 파악 str(df_csv) 'data.frame': 17 obs. of 8 variables: $ name : Factor w/ 17 levels "강수친","김길동",..: 2 12 17 6 10 7 1 14 13 9 ... $ sex : Factor w/ 2 levels "남자","여자": 1 2 1 1 2 2 2 2 1 1 ... $ age : int 23 22 24 23 20 21 22 23 23 22 ... $ grade : int 3 2 4 3 1 2 1 1 3 2 ... $ absence : Factor w/ 2 levels "무","유": 2 1 1 1 2 1 1 1 1 1 ... $ bloodtype: Factor w/ 4 levels "A","AB","B","O": 4 2 3 2 1 4 4 1 3 3 ... $ height : num 165 170 175 182 168 ... $ weight : num 68.2 53 80.1 85.7 49.5 52 45.3 55 64.2 61.3 ...# 변수 선택 1 df_csv$height# 변수 선택 2 (index는 1부터) df_csv[[7]]# 변수 선택 3 df_csv[7]
변수 선택 is(df_csv$height) is(df_csv[[7]]) is(df_csv[7])
벡터 확인 # 여러개의 변수 선택 # csv 파일 불러 오기 df_csv <- read.csv('r-ggagi-data/example_studentlist.csv')df_csv[c(6,7)]
변수 2개 가져오기 df_csv[c('bloodtype','height')]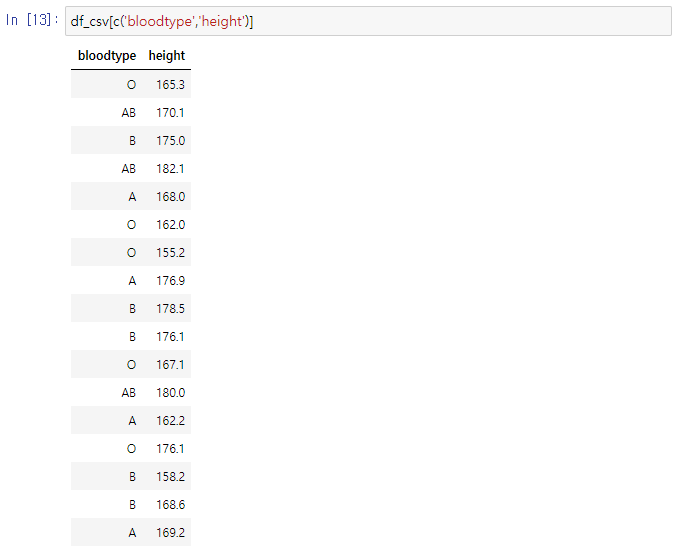
헤더값으로 불러오기 # 행,열 방식으로 가저오기 df_csv[,7]df_csv[2,]df_csv[2,1]
행, 열 방식으로 가져오기 df_csv2 <- read.csv('r-ggagi-data/example_studentlist.csv', stringsAsFactors = F) df_csv2[2,1]# 검색 목록 search()# 검색 목록에 추가 attach(df_csv2)search()# 변수명으로 바로 사용 가능 height# 검색 목록 삭제 detach(df_csv2)
검색 # 조건으로 변수 선택 subset() # csv 파일 불러 오기 df_csv <- read.csv('r-ggagi-data/example_studentlist.csv')# 키가 170보다 큰 관측치 - subset = subset(df_csv, subset = (height > 170))
조건으로 변수 선택 # 특정변수 빼고 보기 - select = subset(df_csv, select = -height)
특정 변수 빼고 보기 # 특정변수 여러개 빼고 보기 - select = subset(df_csv, select = c(-height,-weight))
특정 변수 여러개 빼고 보기 # 변수명 바꾸기 - colname() # csv 파일 불러 오기 df_csv <- read.csv('r-ggagi-data/example_studentlist.csv')# 이름확인하기 colnames(df_csv)# 변수명 이름 바꾸기 colnames(df_csv)[6] <- 'blood' df_csv
이름 확인 및 변수명 변경 # 모든 변수명 바꾸기 old_list <- colnames(df_csv) new_list <- c('na','se','ag','gr','ab','bl','he','we') colnames(df_csv) <- new_list head(df_csv) colnames(df_csv) <- old_list head(df_csv)
모든 변수명 바꾸기 # 새로운 변수 추가 - cbind() bmi <- df_csv$weight/df_csv$height^2 bmidf_bmi <- cbind(df_csv,bmi) df_bmi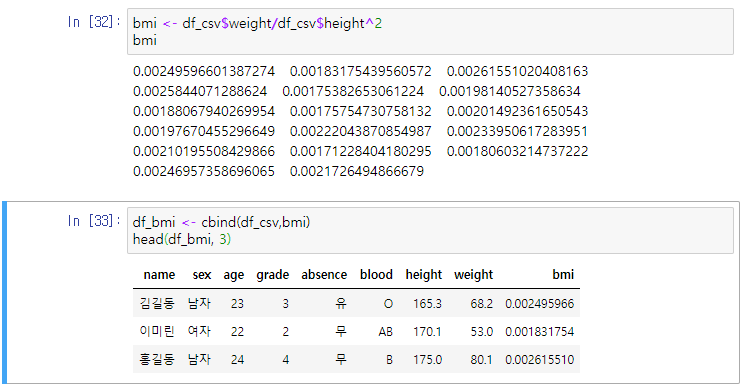
변수 추가 # 2개의 데이터프레임 합치기 - merge() df_1 <- read.csv('r-ggagi-data/example_studentlist.csv') df_2 <- read.csv('r-ggagi-data/omit.csv')df_merge <- merge(df_1, df_2, by='name') df_merge
데이터프레임 합치기 # 행으로 추가하기 - rbind # 같은 이름의 열 이름을 가지고 있어야 함 df_head <- head(df_merge) df_tail <- tail(df_merge)df_rbind <- rbind(df_head, df_tail) df_rbind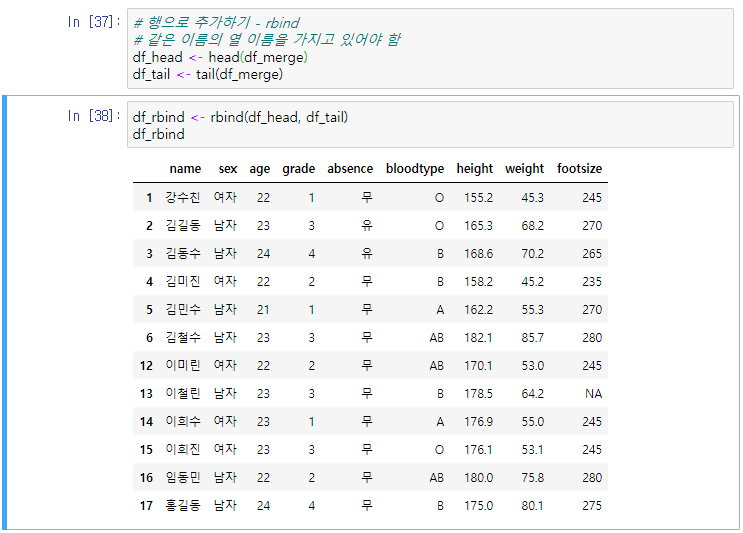
행으로 추가하기 # 모든 종류의 데이터 객체 담기 - list df <- read.csv('r-ggagi-data/example_studentlist.csv') n <- c(1:20) s <- c('a','b','c') b <- c(T,F,T,F,T) tmp_list1 <- list(df, n, s, b, mean)
모든 종류의 데이터 객체 담기 # 이름 넣어 만들기 tmp_list2 <- list(DataFrame=df, Number=n, String=s, Bool=b, Func=mean) tmp_list2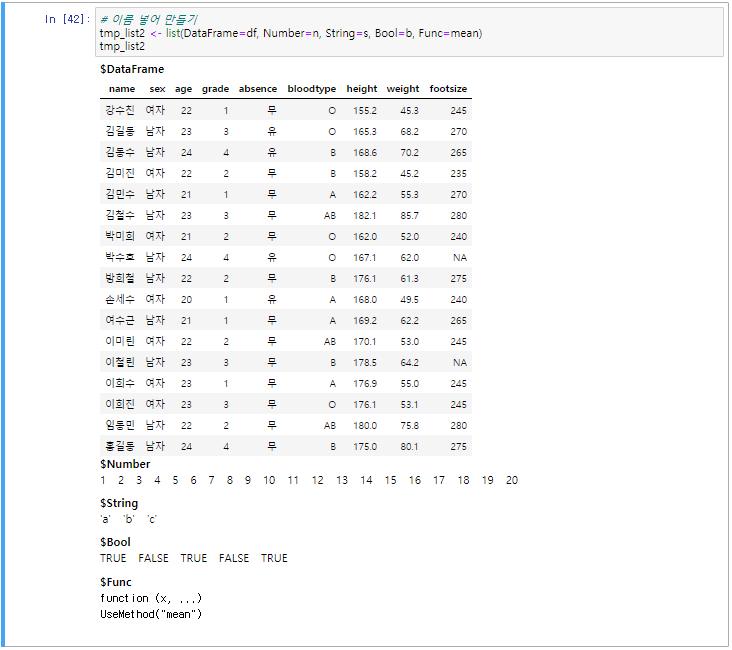
이름 넣어서 만들기 # 항목 삭제 tmp_list1[1] <- NULL tmp_list1# 항목 선택 tmp_list2[2] tmp_list2['Number']
항목 삭제 및 선택 # 자료형 확인 - 함수에 인자로 사용 시 주의 class(tmp_list1[1]) class(tmp_list1[[1]])class(tmp_list2[1]) class(tmp_list2[[1]])# 여러개 항목 선택 tmp_list2[c(2,3)] # list tmp_list2[c('Number','String')] # list tmp_list2$Number # integer tmp_list2$String # character
자료형 확인 및 여러개 항목 선택 # 리스트 모든 항목에 동일 함수 적용 df <- read.csv('r-ggagi-data/example_studentlist.csv')# 성별에 따른 키값을 리스트로 반환 - split height_sex <- split(df$height, df$sex) height_sex# 리스트 평균 구하기 mean(height_sex) mean(height_sex[1]) mean(height_sex[[1]])
키값을 리스트로 반환, 리스트 평균 구하기 height_sex_mean <- sapply(height_sex, mean) height_sex_mean height_sex_mean[1] height_sex_mean[[1]]# 리스트 표준편차 구하기 height_sex_sd <- sapply(height_sex, sd) height_sex_sd height_sex_sd[1] height_sex_sd[[1]]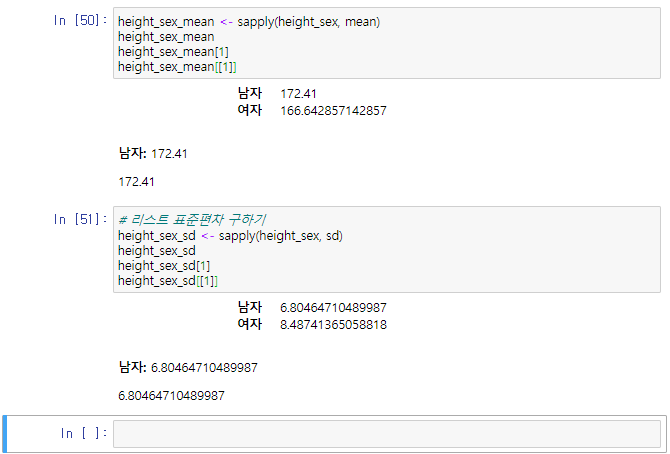
평균 및 표준편차 # 리스트 범위 구하기 height_sex_range <- sapply(height_sex, range) height_sex_range height_sex_range[1,] # 행 height_sex_range[,1] # 열# 명목형 변수 도수분포표 만들기 df <- read.csv('r-ggagi-data/example_studentlist.csv')# 빈도수 - table() blood_type_table <- table(df$bloodtype) blood_type_table# 상대도수 - prop.table blood_type_prop_table <- prop.table(blood_type_table) blood_type_prop_table
리스트 범위, 빈도수, 상대도수 # 함께 보기 - rbind blood_type_rbind <- rbind(blood_type_table, blood_type_prop_table) blood_type_rbind# table 객체 합구하기 - addmargins() # margin : 1 열, 2 행, 생략시 행열의 합 blood_type_rbind_sum <- addmargins(blood_type_rbind, margin = 2) blood_type_rbind_sum# 연속형 변수 도수분포표 만들기 # 구간을 먼저 나눈다 - 계급# 4개의 구간으로 나누기 - cut() # ( - 미포함 ] - 포함 height_break_4 <- cut(df$height, breaks = 4) height_break_4
객체 합, 구간 나누기 # 빈도수 - table() height_break_4_table <- table(height_break_4) height_break_4_table height_break_4# 상대도수 - prop.table height_break_4_prop_table <- prop.table(height_break_4_table) height_break_4_prop_table height_break_4# 함께 보기 - rbind height_break_4_rbind <- rbind(height_break_4_table, height_break_4_prop_table) height_break_4_rbind# 누적상대도수 - cumsum() height_break_4_cumsum <- rbind(height_break_4_rbind, cumsum(height_break_4_rbind[2,])) height_break_4_cumsum# 이름 추가(변경) rownames(height_break_4_cumsum) <- c('도수','상대도수','누적도수') height_break_4_cumsum
결과창 # 분할표 만들기 - 두 변수의 빈도수를 나타내는 표 df <- read.csv('r-ggagi-data/example_studentlist.csv')# 빈도수 구하기 - table sex_blood_table <- table(df$sex, df$bloodtype) sex_blood_table# 도수 행, 열 합 구하기 - addmargins addmargins(sex_blood_table)# 상대도수 구하기 sex_blood_prop_table <- prop.table(sex_blood_table) sex_blood_prop_table# 상대도수 합 구하기 addmargins(sex_blood_prop_table)
빈도수, 상대도수, 합 구하기 # 행별 상대도수 구하기 sex_blood_prop_table_margin_1 <- prop.table(sex_blood_table, margin = 1) sex_blood_prop_table_margin_1# 열별 상대도수 구하기 sex_blood_prop_table_margin_2 <- prop.table(sex_blood_table, margin = 2) sex_blood_prop_table_margin_2# 결측치 NA - 값이 없는 경우 처리 # complete.cases() - NA값을 조사해 논리값으로 반환 # na.omit() - 행에 NA 가 있으면 행 삭제 a <- c(1,2,3,4,NA,6,7,8,9,10) complete.cases(a)a[complete.cases(a)]na.omit(a)
행, 열별 상대도수 / 결측치 'R' 카테고리의 다른 글
기술통계 (0) 2020.07.06 데이터 개념 예제로 이해하기 (0) 2020.07.06 R 필수 설치 패키지 (0) 2020.07.02 Python 가상환경 생성 및 R 주피터 노트북 연결 (0) 2020.07.02 R 기초 (0) 2020.07.02 -