-
KoNLP(자연어처리)Python 2020. 7. 22. 17:25
자연어 처리 시작하기
-
설치 목록
-
JDK (Java SE Downloads)
-
JAVA_HOME 설정
-
JPype 설치 (https://lovit.github.io/nlp/2018/07/06/java_in_python/)
-
KoNLPy 설치 (Lucy Park님이 개발 https://pinkwink.kr/1025)
-
nltk 설치(https://wikidocs.net/22488), https://datascienceschool.net/view-notebook/8895b16a141749a9bb381007d52721c1/
-
Word Cloud 설치
-
한글 자연어 처리 기초 - KoNLPy 및 필요 모듈의 설치
-
콘다 콘솔에서 설치
-
KoNLPy : pip install konlpy
-
JPype1 : conda install -c conda-forge jpype1 - console에서 실행
-
JPype1는 KoNLPy 0.5.x 버전 설치시 자동 설치됨(0.4.x 버전에서 필요)
-
이후 Jupyter Notebook 재실행 필요
-
-
JDK 설치 : Java JDK로 검색해서 OS에 맞춰 설치
-
pip install nltk
-
pip install wordcloud
# 학습을 위한 패키지 설치 # All Packages Download import nltk nltk.download()showing info https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/index.xml True#jpype 설치 확인 konlpy 오류시 확인 #import jpype #pype.startJVM(jpype.getDefaultJVMPath())한글 자연어 처리 기초
# 꼬꼬마 모듈 from konlpy.tag import Kkma kkma = Kkma()# 문장 분석 : 마침표가 없어도 구분 kkma.sentences('한국어 분석을 시작합니다 재미있어요~~')['한국어 분석을 시작합니다', '재미있어요~~']# 명사 분석 kkma.nouns('한국어 분석을 시작합니다 재미있어요~~')['한국어', '분석']# 형태소 분석 : 형태소(최소한의 의미 단어) kkma.pos('한국어 분석을 시작합니다 재미있어요~~')[('한국어', 'NNG'), ('분석', 'NNG'), ('을', 'JKO'), ('시작하', 'VV'), ('ㅂ니다', 'EFN'), ('재미있', 'VA'), ('어요', 'EFN'), ('~~', 'SW')]txt = '한국어 분석을 시작합니다 재미있어요~~'# 한나눔 사용 from konlpy.tag import Hannanum hannanum = Hannanum()# 명사 분석 hannanum.nouns(txt)['한국어', '분석', '시작']# 형태소 분석(설명 안나옴) hannanum.morphs(txt)['한국어', '분석', '을', '시작', '하', 'ㅂ니다', '재미있', '어요', '~~']# 형태소 분석 hannanum.pos(txt)[('한국어', 'N'), ('분석', 'N'), ('을', 'J'), ('시작', 'N'), ('하', 'X'), ('ㅂ니다', 'E'), ('재미있', 'P'), ('어요', 'E'), ('~~', 'S')]#from konlpy.tag import Twitter from konlpy.tag import Okt #t = Twitter() t = Okt()# 명사 분석 t.nouns(txt)['한국어', '분석', '시작']t.morphs(txt)['한국어', '분석', '을', '시작', '합니다', '재미있어요', '~~']t.pos(txt)[('한국어', 'Noun'), ('분석', 'Noun'), ('을', 'Josa'), ('시작', 'Noun'), ('합니다', 'Verb'), ('재미있어요', 'Adjective'), ('~~', 'Punctuation')]워드 클라우드
-
WordCloud 설치 : pip install wordcloud
-
자주 나타나는 단어를 크게 보여주는 시각화
-
wordcloud 모듈 자체가 빈도를 계산하는 기능
from wordcloud import WordCloud, STOPWORDS import numpy as np from PIL import Image# 이상한 나라의 엘리스 text = open('DataScience_Ing/data/09. alice.txt').read() alice_mask = np.array(Image.open('DataScience_Ing/data/09. alice_mask.png')) # 카운트 하지 않게 하기 - said란 단어가 많이 나오나?? stopwords = set(STOPWORDS) stopwords.add('said')import matplotlib.pyplot as plt import platform #폰트 설정 path = "c:/Windows/Fonts/malgun.ttf" from matplotlib import font_manager, rc if platform.system() == 'Darwin': rc('font', family='AppleGothic') elif platform.system() == 'Windows': font_name = font_manager.FontProperties(fname=path).get_name() rc('font', family=font_name) else: print('Unknown system... sorry~~~~') %matplotlib inlineplt.figure(figsize=(8,8)) plt.imshow(alice_mask, cmap=plt.cm.gray, interpolation='bilinear') plt.axis('off') plt.show()
# Alice 1등 wc = WordCloud(background_color='white', max_words=2000, mask=alice_mask, stopwords=stopwords) wc = wc.generate(text) #wc.words_# 그림에 겹처 보이게 # interpolation='bilinear'(선형 보간법) : https://blog.naver.com/aorigin/220947541918 plt.figure(figsize=(12,12)) plt.imshow(wc, interpolation='bilinear') plt.axis('off') plt.show()
앨리스 그림처럼 word로 채워짐 # 스타워즈 A New Hope text = open('DataScience_Ing/data/09. a_new_hope.txt').read() text = text.replace('HAN', 'Han') text = text.replace("LUKE'S", 'Luke') mask = np.array(Image.open('DataScience_Ing/data/09. stormtrooper_mask.png'))stopwords = set(STOPWORDS) stopwords.add("int") stopwords.add("ext")wc = WordCloud(max_words=1000, mask=mask, stopwords=stopwords, margin=10, random_state=1).generate(text) default_colors = wc.to_array()import random def grey_color_func(word, font_size, position, orientation, random_state=None, **kwargs): return 'hsl(0, 0%%, %d%%)' % random.randint(60, 100)plt.figure(figsize=(12,12)) plt.imshow(wc.recolor(color_func=grey_color_func, random_state=3), interpolation='bilinear') plt.axis('off') plt.show()
육아휴직관련 법안 대한민국 국회 제 1809890호 의한
from konlpy.corpus import kobill files_ko = kobill.fileids() doc_ko = kobill.open('1809890.txt').read()doc_ko'지방공무원법 일부개정법률안\n\n(정의화의원 대표발의 )\n\n 의 안\n 번 호\n\n9890\n\n발의연월일 : 2010. 11. 12. \n\n발 의 자 : 정의화․이명수․김을동 \n\n이사철․여상규․안규백\n\n황영철․박영아․김정훈\n\n김학송 의원(10인)\n\n제안이유 및 주요내용\n\n 초등학교 저학년의 경우에도 부모의 따뜻한 사랑과 보살핌이 필요\n\n한 나이이나, 현재 공무원이 자녀를 양육하기 위하여 육아휴직을 할 \n\n수 있는 자녀의 나이는 만 6세 이하로 되어 있어 초등학교 저학년인 \n\n자녀를 돌보기 위해서는 해당 부모님은 일자리를 그만 두어야 하고 \n\n이는 곧 출산의욕을 저하시키는 문제로 이어질 수 있을 것임.\n\n 따라서 육아휴직이 가능한 자녀의 연령을 만 8세 이하로 개정하려\n\n는 것임(안 제63조제2항제4호).\n\n- 1 -\n\n\x0c법률 제 호\n\n지방공무원법 일부개정법률안\n\n지방공무원법 일부를 다음과 같이 개정한다.\n\n제63조제2항제4호 중 “만 6세 이하의 초등학교 취학 전 자녀를”을 “만 \n\n8세 이하(취학 중인 경우에는 초등학교 2학년 이하를 말한다)의 자녀를”\n\n로 한다.\n\n부 칙\n\n이 법은 공포한 날부터 시행한다.\n\n- 3 -\n\n\x0c신 ·구조문대비표\n\n현 행\n\n개 정 안\n\n제63조(휴직) ① (생 략)\n\n제63조(휴직) ① (현행과 같음)\n\n ② 공무원이 다음 각 호의 어\n\n ② -------------------------\n\n느 하나에 해당하는 사유로 휴\n\n----------------------------\n\n직을 원하면 임용권자는 휴직\n\n----------------------------\n\n을 명할 수 있다. 다만, 제4호\n\n-------------.---------------\n\n의 경우에는 대통령령으로 정\n\n----------------------------\n\n하는 특별한 사정이 없으면 휴\n\n----------------------------\n\n직을 명하여야 한다.\n\n--------------.\n\n 1. ∼ 3. (생 략)\n\n 1. ∼ 3. (현행과 같음)\n\n 4. 만 6세 이하의 초등학교 취\n\n 4. 만 8세 이하(취학 중인 경우\n\n학 전 자녀를 양육하기 위하\n\n에는 초등학교 2학년 이하를 \n\n여 필요하거나 여자공무원이 \n\n말한다)의 자녀를 ----------\n\n임신 또는 출산하게 되었을 \n\n---------------------------\n\n때\n\n---------------------------\n\n 5.⋅6. (생 략)\n\n ③⋅④ (생 략)\n\n--------\n\n 5.⋅6. (현행과 같음)\n\n ③⋅④ (현행과 같음)\n\n- 5 -\n\n\x0c지방공무원법 일부개정법률안 등 비용추계서 미첨부사유서\n1. 재정수반요인\n\n개정안에서 「국가공무원법」 제71조제2항제4호 중 국가공무원의 육아\n\n휴직 가능 자녀의 연령을 만6세 이하에서 만8세 이하로 하고, 「지방공\n\n무원법」 제63조제2항제4호 중 지방공무원의 육아휴직 가능 자녀의 연\n\n령을 만6세 이하에서 만8세 이하로 하고, 「교육공무원법」 제44조제1항\n\n제7조 중 교육공무원의 육아휴직 가능 자녀의 연령을 만6세 이하에서 \n\n만8세 이하로 하고, 「남녀고용평등과 일․가정 양립지원에 관한 법률」 \n\n제19조제1항 중 근로자 육아휴직 가능 자녀연령을 만6세 이하에서 만\n\n8세 이하로 조정함에 따라 추가 재정소요가 예상됨.\n\n2. 미첨부 근거 규정\n「의안의 비용추계에 관한 규칙」 제3조제1항 단서 중 제1호(예상되는 비용이 연평균 10억원 미만\n이거나 한시적인 경비로서 총 30억원 미만인 경우)에 해당함.\n\n3. 미첨부 사유\n\n개정안에서 국가․지방․교육공무원 및 근로자가 육아휴직을 신청할 \n\n수 있는 자녀의 연령을 만6세 이하에서 만8세 이하로 상향조정함에 \n\n따라 추가 재정소요가 예상된다. 동 법률 개정안이 2011년에 시행된다\n\n고 가정한 경우, 2010년 현재 자녀의 연령이 7세이고 육아휴직을 신청\n\n- 7 -\n\n\x0c- 8 -\n\n하지 않은 국가․지방․교육공무원 및 근로자가 대상이 된다.\n\n대상연령의 확대됨에 따라 육아휴직신청자의 수가 어느 정도 늘어날 \n\n것으로 예상된다. 이 경우 발생하는 비용은 현행법에 따르면 월50만원\n\n이나 현재 관련법령 개정이 추진되고 있으며, 이에 따라 2011년에는 \n\n육아휴직자가 지급받는 월급여액에 비례하여 육아휴직급여가 지급되\n\n기 때문에 법령개정을 가정하고 추계한다. 이러한 경우 육아휴직급여\n\n액은 육아휴직자가 지급받는 월급여의 40%에 해당한다. 육아휴직자가 \n\n발생한 경우 발생하는 비용은 대체인력 고용인건비와 육아휴직자가 \n\n받는 월급여액의 40%이다. 이와 대비하여 육아휴직자에게 지급하던 \n\n임금은 더 이상 발생하지 않는다. 따라서 실제 발생하는 순비용은 육\n\n아휴직자에게 지급하던 월 급여액과 연령 확대에 따라 발생하는 비용\n\n인 육아휴직자가 받던 월급여액의 40%와 대체인력 고용인건비의 차\n\n액인데 이 값이 0보다 크면 추가 재정소요는 발생하지 않는다고 볼 \n\n수 있다.\n\n추가비용 발생여부를 정확하게 알아보기 위하여 비용에 대한 수리모\n\n델을 만들고 이에 따라 비용발생 여부를 알아보기로 하자. 모델에 사\n\n용되는 변수를 다음과 같이 정의한다.\n\n발생비용 : N×p×X + N×육아휴직급여액 - N×P\n\nN\n\nP\n\n: 육아휴직대상자의 수\n\n: 육아휴직대상자의 월급여액\n\n\x0cp\n\nX\n\n: 육아휴직자가 발생한 경우 대체 고용할 확률\n\n: 대체 고용한 인력에게 지급하는 월급여액\n\n위의 수식에서 육아휴직급여액은 육아휴직자 월급여액의 40%까지 지\n\n급할 예정이므로 육아휴직급여액은 P×40%이다. 육아휴직자가 발생한 \n\n경우 대체 고용할 확률 p는 고용노동부의 육아휴직 관련 자료를 이용\n\n한다. 고용노동부에 따르면 2011년의 경우 육아휴직급여 대상자는 \n\n40,923명이며, 육아휴직에 따른 대체인력 고용 예상인원은 2,836명이\n\n다. 2007년부터 2011년까지의 현황을 정리하면 다음의 [표]와 같다.\n\n[표] 육아휴직급여 수급자의 수 및 대체인력 고용 현황: 2007~2011년\n\n(단위: 명, % )\n\n2007\n\n2008\n\n2009\n\n2010\n\n2011\n\n평균\n\n육아휴직급여 수급자(A)\n\n21,185\n\n29,145\n\n35,400\n\n41,291\n\n43,899\n\n34,184\n\n대체인력 채용(B)\n\n796\n\n1,658\n\n1,957\n\n2,396\n\n2,836\n\n1,929\n\n비 율(B/A)\n\n3.8\n\n5.7\n\n5.5\n\n5.8\n\n6.5\n\n5.6\n\n자료: 고용노동부 자료를 바탕으로 국회예산정책처 작성\n\n위의 [표]의 자료에 따라 육아휴직자가 발생한 경우 대체 고용할 확률 \n\np의 값은 5.6%라고 가정한다. 그리고 비용이 발생한다고 가정하여 위\n\n의 수식을 다시 작성하면 다음의 수식과 같다.\n\nN×p×X + N×육아휴직급여액 - N×P > 0\n\n(1)\n\n- 9 -\n\n\x0c- 10 -\n\nN×5.6%×X + N×P×40% - N×P > 0\n\n0.056×X > 0.6P\n\nX > 10.7×P\n\n(2)\n\n(3)\n\n(5)\n\n위의 수식에 육아휴직자가 받는 월 급여액을 대입하여 대체고용인력\n\n자에게 지급하는 월 급여액을 추정하여 보자. 육아휴직자가 월 200만\n\n원을 받는다고 가정하면, 대체고용인력자에게 육아휴직자가 받는 월 \n\n급여액의 10.7배에 달하는 월 21,428,571원 이상을 지급해야 추가 비용\n\n이 발생한다. 대체고용인력자에게 육아휴직자보다 더 많은 월급여액을 \n\n주지는 않을 것이고 그리고 10여배 이상 월급을 주지도 않을 것이기 \n\n때문에 추가 비용이 발생한다고 보기 힘들다. 위의 수식에서 대체인력 \n\n고용확률 p를 20%로 가정하더라도(이 경우 X > 3×P) 200만원 받는 \n\n육아휴직자 대체인력에게 월 600만원 이상을 지급해야 추가 비용이 \n\n발생한다.\n\n행정안전부의 통계자료(행정안전부 통계연감)에서는 지방공무원의 육\n\n아휴직 현황자료를 보여주고 있다. 여기서 육아휴직자가 발생한 경우 \n\n대체인력을 주로 임용대기자 또는 일용직을 활용하는 것으로 보인다. \n\n따라서 공무원의 경우에도 [표]에서 보여주는 일반기업체의 대체인력 \n\n고용확률과 차이는 크지 않을 것으로 보인다.\n\n이상의 논의를 바탕으로 육아휴직기간을 만6에서 만8세로 연장하더라\n\n도 법률 개정에 따른 추가 비용은 발생하지 않을 것으로 예상된다.\n\n\x0c4. 작성자\n\n국회예산정책처 법안비용추계1팀\n\n팀 장 정 문 종\n\n예산분석관 김 태 완\n\n(02-788-4649, tanzania@assembly.go.kr)\n\n- 11 -\n\n\x0c'#from konlpy.tag import Twitter from konlpy.tag import Okt #t = Twitter() t = Okt() tokens_ko = t.nouns(doc_ko) #tokens_ko# 빈도수 처리 ko = nltk.Text(tokens_ko, name='대한민국 국회 의안 제 1809890호')print(len(ko.tokens)) # returns number of tokens (document length) print(len(set(ko.tokens))) # returns number of unique tokens # 빈도수로 정리 ko.vocab() # returns frequency distribution735 250 FreqDist({'육아휴직': 38, '발생': 19, '만': 18, '이하': 18, '비용': 17, '액': 17, '경우': 16, '세': 16, '자녀': 14, '고용': 14, ...})plt.figure(figsize=(12, 6)) ko.plot(50) plt.show()
# 제외 문자 처리 stop_words = ['.', '(', ')', ',', "'", '%', '-', 'X', ').', '×','의','자','에','안','번', '호','을','이','다','만','로','가','를'] ko = [each_word for each_word in ko if each_word not in stop_words] #koko = nltk.Text(ko, name='대한민국 국회 의안 제 1809890호') plt.figure(figsize=(12, 6)) ko.plot(50) # Plot sorted frequency of top 50 tokens plt.show()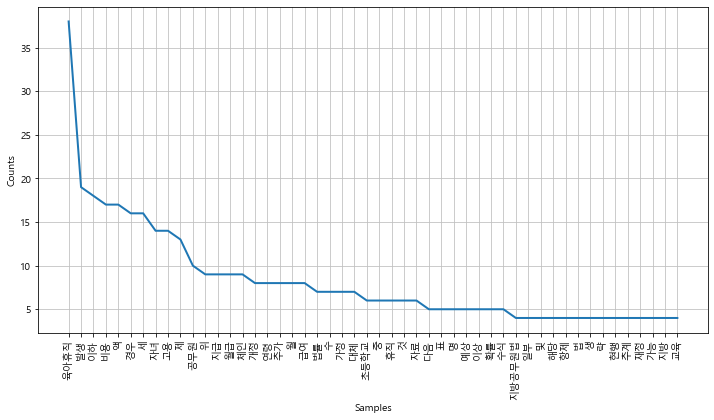
ko.count('초등학교')6plt.figure(figsize=(12, 6)) ko.dispersion_plot(['육아휴직', '초등학교', '공무원'])
# 단어 주변부 확인 ko.concordance('초등학교')Displaying 6 of 6 matches: 안규백 황영철 박영아 김정훈 김학송 의원 인 제안 이유 및 내용 초등학교 저학년 경우 부모 사랑 필요 나이 현재 공무원 자녀 양육 위 육아 나이 현재 공무원 자녀 양육 위 육아휴직 수 자녀 나이 세 이하 초등학교 저학년 자녀 위 해당 부모님 일자리 곧 출산 의욕 저하 문제 수 일부 개정 법률 지방공무원법 일부 다음 개정 제 항제 중 세 이하 초등학교 취학 전 자녀 세 이하 취학 중인 경우 초등학교 학년 이하 말 자 항제 중 세 이하 초등학교 취학 전 자녀 세 이하 취학 중인 경우 초등학교 학년 이하 말 자녀 부 칙 법 공포 날 시행 신 구조 문대비 표 수 다만 제 경우 대통령령 정 사정 직 명 생 략 현행 세 이하 초등학교 취 세 이하 취학 중인 경우 학 전 자녀 양육 위 초등학교 학년 이하 초등학교 취 세 이하 취학 중인 경우 학 전 자녀 양육 위 초등학교 학년 이하 여 여자 공무원 말 자녀 임신 출산 때 생 략 생 략# 연이어 사용된 단어 확인 ko.collocations()초등학교 저학년; 근로자 육아휴직; 육아휴직 대상자; 공무원 육아휴직data = ko.vocab().most_common(150) # for window : font_path='c:/Windows/Fonts/malgun.ttf' # for mac : font_path='/Library/Fonts/AppleGothic.ttf' wordcloud = WordCloud(font_path='c:/Windows/Fonts/malgun.ttf', relative_scaling = 0.2, background_color = 'white', ).generate_from_frequencies(dict(data)) plt.figure(figsize=(12, 8)) plt.imshow(wordcloud) plt.axis('off') plt.show()
Naive Bayes Classifier의 이해 - 영문
-
지도학습의 한 종류 (지도학습은 항상 답이 정해져있음)
-
두 사건을 독립이라고 사정하고 각각의 조건부 확률을 가지고 분류
from nltk.tokenize import word_tokenize import nltk# pos 긍정, neg 부정의 태그가 있는 지도학습용 Data train = [('i like you', 'pos'), ('i hate you', 'neg'), ('you like me', 'neg'), ('i like her', 'pos')]# 말뭉치 all_words = set(word.lower() for sentence in train for word in word_tokenize(sentence[0])) all_words{'hate', 'her', 'i', 'like', 'me', 'you'}# 벡터화 한다 # 말뭉치를 기준으로 train 정보 존재 확인 t = [({word: (word in word_tokenize(x[0])) for word in all_words}, x[1]) for x in train] t[({'you': True, 'like': True, 'i': True, 'me': False, 'her': False, 'hate': False}, 'pos'), ({'you': True, 'like': False, 'i': True, 'me': False, 'her': False, 'hate': True}, 'neg'), ({'you': True, 'like': True, 'i': False, 'me': True, 'her': False, 'hate': False}, 'neg'), ({'you': False, 'like': True, 'i': True, 'me': False, 'her': True, 'hate': False}, 'pos')]classifier = nltk.NaiveBayesClassifier.train(t) classifier.show_most_informative_features() # hate = False pos : neg = 1.7 : 1.0 => hate가 없을 때 # 긍정과 부정의 비율 1.7:1 이라는 의미Most Informative Features hate = False pos : neg = 1.7 : 1.0 her = False neg : pos = 1.7 : 1.0 i = True pos : neg = 1.7 : 1.0 like = True pos : neg = 1.7 : 1.0 me = False pos : neg = 1.7 : 1.0 you = True neg : pos = 1.7 : 1.0test_sentence = 'i like MeRui' test_sent_features = {word.lower(): (word in word_tokenize(test_sentence.lower())) for word in all_words} test_sent_features{'you': False, 'like': True, 'i': True, 'me': False, 'her': False, 'hate': False}classifier.classify(test_sent_features)'pos'Naive Bayes Classifier의 이해 - 한글
#from konlpy.tag import Twitter from konlpy.tag import Okt#pos_tagger = Twitter() pos_tagger = Okt()train = [('메리가 좋아', 'pos'), ('고양이도 좋아', 'pos'), ('난 수업이 지루해', 'neg'), ('메리는 이쁜 고양이야', 'pos'), ('난 마치고 메리랑 놀거야', 'pos')]# 말뭉치 만들기 all_words = set(word.lower() for sentence in train for word in word_tokenize(sentence[0])) all_words # 메리가 와 메리는 메리랑 별도 구분{'고양이도', '고양이야', '난', '놀거야', '마치고', '메리가', '메리는', '메리랑', '수업이', '이쁜', '좋아', '지루해'}t = [({word: (word in word_tokenize(x[0])) for word in all_words}, x[1]) for x in train] t[({'메리가': True, '좋아': True, '이쁜': False, '난': False, '마치고': False, '수업이': False, '고양이도': False, '지루해': False, '메리랑': False, '고양이야': False, '놀거야': False, '메리는': False}, 'pos'), ({'메리가': False, '좋아': True, '이쁜': False, '난': False, '마치고': False, '수업이': False, '고양이도': True, '지루해': False, '메리랑': False, '고양이야': False, '놀거야': False, '메리는': False}, 'pos'), ({'메리가': False, '좋아': False, '이쁜': False, '난': True, '마치고': False, '수업이': True, '고양이도': False, '지루해': True, '메리랑': False, '고양이야': False, '놀거야': False, '메리는': False}, 'neg'), ({'메리가': False, '좋아': False, '이쁜': True, '난': False, '마치고': False, '수업이': False, '고양이도': False, '지루해': False, '메리랑': False, '고양이야': True, '놀거야': False, '메리는': True}, 'pos'), ({'메리가': False, '좋아': False, '이쁜': False, '난': True, '마치고': True, '수업이': False, '고양이도': False, '지루해': False, '메리랑': True, '고양이야': False, '놀거야': True, '메리는': False}, 'pos')]classifier = nltk.NaiveBayesClassifier.train(t) # 공부시킴 classifier.show_most_informative_features()Most Informative Features 난 = True neg : pos = 2.5 : 1.0 좋아 = False neg : pos = 1.5 : 1.0 고양이도 = False neg : pos = 1.1 : 1.0 고양이야 = False neg : pos = 1.1 : 1.0 놀거야 = False neg : pos = 1.1 : 1.0 마치고 = False neg : pos = 1.1 : 1.0 메리가 = False neg : pos = 1.1 : 1.0 메리는 = False neg : pos = 1.1 : 1.0 메리랑 = False neg : pos = 1.1 : 1.0 이쁜 = False neg : pos = 1.1 : 1.0test_sentence = '난 수업이 마치면 메리랑 놀거야'test_sent_features = {word: (word in word_tokenize(test_sentence)) for word in all_words} test_sent_features{'메리가': False, '좋아': False, '이쁜': False, '난': True, '마치고': False, '수업이': True, '고양이도': False, '지루해': False, '메리랑': True, '고양이야': False, '놀거야': True, '메리는': False}# neg => 한글을 다룰 때는 형태소 분석이 필요해짐 classifier.classify(test_sent_features)'neg'# https://datascienceschool.net/view-notebook/70ce46db4ced4a999c6ec349df0f4eb0/ # pos() 품사 부착 def tokenize(doc): return ['/'.join(t) for t in pos_tagger.pos(doc, norm=True, stem=True)]# 태그부착 train_docs = [(tokenize(row[0]), row[1]) for row in train] train_docs[(['메리/Noun', '가/Josa', '좋다/Adjective'], 'pos'), (['고양이/Noun', '도/Josa', '좋다/Adjective'], 'pos'), (['난/Noun', '수업/Noun', '이/Josa', '지루하다/Adjective'], 'neg'), (['메리/Noun', '는/Josa', '이쁘다/Adjective', '고양이/Noun', '야/Josa'], 'pos'), (['난/Noun', '마치/Noun', '고/Josa', '메리/Noun', '랑/Josa', '놀다/Verb'], 'pos')]# 말뭉치 재작업 tokens = [t for d in train_docs for t in d[0]] tokens['메리/Noun', '가/Josa', '좋다/Adjective', '고양이/Noun', '도/Josa', '좋다/Adjective', '난/Noun', '수업/Noun', '이/Josa', '지루하다/Adjective', '메리/Noun', '는/Josa', '이쁘다/Adjective', '고양이/Noun', '야/Josa', '난/Noun', '마치/Noun', '고/Josa', '메리/Noun', '랑/Josa', '놀다/Verb']# 말뭉치에 단어 존재 여부 확인 함수 def term_exists(doc): return {word: (word in set(doc)) for word in tokens}# 훈련데이터에 적용 train_xy = [(term_exists(d), c) for d,c in train_docs] train_xy[({'메리/Noun': True, '가/Josa': True, '좋다/Adjective': True, '고양이/Noun': False, '도/Josa': False, '난/Noun': False, '수업/Noun': False, '이/Josa': False, '지루하다/Adjective': False, '는/Josa': False, '이쁘다/Adjective': False, '야/Josa': False, '마치/Noun': False, '고/Josa': False, '랑/Josa': False, '놀다/Verb': False}, 'pos'), ({'메리/Noun': False, '가/Josa': False, '좋다/Adjective': True, '고양이/Noun': True, '도/Josa': True, '난/Noun': False, '수업/Noun': False, '이/Josa': False, '지루하다/Adjective': False, '는/Josa': False, '이쁘다/Adjective': False, '야/Josa': False, '마치/Noun': False, '고/Josa': False, '랑/Josa': False, '놀다/Verb': False}, 'pos'), ({'메리/Noun': False, '가/Josa': False, '좋다/Adjective': False, '고양이/Noun': False, '도/Josa': False, '난/Noun': True, '수업/Noun': True, '이/Josa': True, '지루하다/Adjective': True, '는/Josa': False, '이쁘다/Adjective': False, '야/Josa': False, '마치/Noun': False, '고/Josa': False, '랑/Josa': False, '놀다/Verb': False}, 'neg'), ({'메리/Noun': True, '가/Josa': False, '좋다/Adjective': False, '고양이/Noun': True, '도/Josa': False, '난/Noun': False, '수업/Noun': False, '이/Josa': False, '지루하다/Adjective': False, '는/Josa': True, '이쁘다/Adjective': True, '야/Josa': True, '마치/Noun': False, '고/Josa': False, '랑/Josa': False, '놀다/Verb': False}, 'pos'), ({'메리/Noun': True, '가/Josa': False, '좋다/Adjective': False, '고양이/Noun': False, '도/Josa': False, '난/Noun': True, '수업/Noun': False, '이/Josa': False, '지루하다/Adjective': False, '는/Josa': False, '이쁘다/Adjective': False, '야/Josa': False, '마치/Noun': True, '고/Josa': True, '랑/Josa': True, '놀다/Verb': True}, 'pos')]# 분류기 동작 classifier = nltk.NaiveBayesClassifier.train(train_xy)# 형태소 분석 전 neg test_sentence = [("난 수업이 마치면 메리랑 놀거야")]test_docs = pos_tagger.pos(test_sentence[0]) test_docs[('난', 'Noun'), ('수업', 'Noun'), ('이', 'Josa'), ('마치', 'Noun'), ('면', 'Josa'), ('메리', 'Noun'), ('랑', 'Josa'), ('놀거야', 'Verb')]classifier.show_most_informative_features()Most Informative Features 난/Noun = True neg : pos = 2.5 : 1.0 메리/Noun = False neg : pos = 2.5 : 1.0 고양이/Noun = False neg : pos = 1.5 : 1.0 좋다/Adjective = False neg : pos = 1.5 : 1.0 가/Josa = False neg : pos = 1.1 : 1.0 고/Josa = False neg : pos = 1.1 : 1.0 놀다/Verb = False neg : pos = 1.1 : 1.0 는/Josa = False neg : pos = 1.1 : 1.0 도/Josa = False neg : pos = 1.1 : 1.0 랑/Josa = False neg : pos = 1.1 : 1.0test_sent_features = {word: (word in tokens) for word in test_docs} test_sent_features{('난', 'Noun'): False, ('수업', 'Noun'): False, ('이', 'Josa'): False, ('마치', 'Noun'): False, ('면', 'Josa'): False, ('메리', 'Noun'): False, ('랑', 'Josa'): False, ('놀거야', 'Verb'): False}# pos 로 분류 classifier.classify(test_sent_features)'pos'문장의 유사도 측정
-
어떤 문장을 벡터로 표현할 수 있다면 벡터간 거리를 구하는 방법으로 해결 가능
from sklearn.feature_extraction.text import CountVectorizer# scikit-learn 텍스트 특징(feature) 추출 모듈 # CountVectorizer 글자를 벡터로 만들어줌 vectorizer = CountVectorizer(min_df = 1)contents = ['메리랑 놀러가고 싶지만 바쁜데 어떻하죠?', '메리는 공원에서 산책하고 노는 것을 싫어해요', '메리는 공원에서 노는 것도 싫어해요. 이상해요.', '먼 곳으로 여행을 떠나고 싶은데 너무 바빠서 그러질 못하고 있어요']# 추출 X = vectorizer.fit_transform(contents) vectorizer.get_feature_names()['것도', '것을', '곳으로', '공원에서', '그러질', '너무', '노는', '놀러가고', '떠나고', '메리는', '메리랑', '못하고', '바빠서', '바쁜데', '산책하고', '싫어해요', '싶은데', '싶지만', '어떻하죠', '여행을', '이상해요', '있어요']# 4개문장 == 4개열로 표현 각 단어 위치가 1의 값을 가짐 메리랑은 첫번째 열 11번째가 1임 X.toarray().transpose()array([[0, 0, 1, 0], [0, 1, 0, 0], [0, 0, 0, 1], [0, 1, 1, 0], [0, 0, 0, 1], [0, 0, 0, 1], [0, 1, 1, 0], [1, 0, 0, 0], [0, 0, 0, 1], [0, 1, 1, 0], [1, 0, 0, 0], [0, 0, 0, 1], [0, 0, 0, 1], [1, 0, 0, 0], [0, 1, 0, 0], [0, 1, 1, 0], [0, 0, 0, 1], [1, 0, 0, 0], [1, 0, 0, 0], [0, 0, 0, 1], [0, 0, 1, 0], [0, 0, 0, 1]], dtype=int64)X = vectorizer.fit_transform(contents) num_samples, num_features = X.shape num_samples, num_features(4, 22)new_post = ['메리랑 공원에서 산책하고 놀고 싶어요'] new_post_vec = vectorizer.transform(new_post) new_post_vec.toarray()array([[0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0]], dtype=int64)# 거리 계산을 위한 함수 호출 # new_post 와 contents의 거리 구하기 # norm 의 의미: https://leebaro.tistory.com/entry/norm%EB%85%B8%EB%A6%84%EC%9D%98-%EC%A0%95%EC%9D%98 import scipy as sp def dist_raw(v1, v2): delta = v1 - v2 return sp.linalg.norm(delta.toarray())# new_post 와 contents의 거리 확인 #best_doc = None best_dist = 65535 best_i = None for i in range(0, num_samples): post_vec = X.getrow(i) d = dist_raw(post_vec, new_post_vec) print('== Post %i with dist = %.2f : %s' %(i, d, contents[i])) if d<best_dist: best_dist = d best_i = i== Post 0 with dist = 2.45 : 메리랑 놀러가고 싶지만 바쁜데 어떻하죠? == Post 1 with dist = 2.24 : 메리는 공원에서 산책하고 노는 것을 싫어해요 == Post 2 with dist = 2.65 : 메리는 공원에서 노는 것도 싫어해요. 이상해요. == Post 3 with dist = 3.46 : 먼 곳으로 여행을 떠나고 싶은데 너무 바빠서 그러질 못하고 있어요# 좀더 한글 문장에 맞게 벡터화 진행 # from konlpy.tag import Twitter # t = Twitter() from konlpy.tag import Okt t = Okt()# morphs() 형태소 추출 contents_tokens = [t.morphs(row) for row in contents] contents_tokens[['메리', '랑', '놀러', '가고', '싶지만', '바쁜데', '어떻하죠', '?'], ['메리', '는', '공원', '에서', '산책', '하고', '노', '는', '것', '을', '싫어해요'], ['메리', '는', '공원', '에서', '노', '는', '것', '도', '싫어해요', '.', '이상해요', '.'], ['먼', '곳', '으로', '여행', '을', '떠나고', '싶은데', '너무', '바빠서', '그러질', '못', '하고', '있어요']]# 형태소 분석 후 띄어쓰기로 구분하고 하나의 문장(sentence)으로 만들기 contents_for_vectorize = [] for content in contents_tokens: sentence = '' for word in content: sentence = sentence + ' ' + word contents_for_vectorize.append(sentence) contents_for_vectorize[' 메리 랑 놀러 가고 싶지만 바쁜데 어떻하죠 ?', ' 메리 는 공원 에서 산책 하고 노 는 것 을 싫어해요', ' 메리 는 공원 에서 노 는 것 도 싫어해요 . 이상해요 .', ' 먼 곳 으로 여행 을 떠나고 싶은데 너무 바빠서 그러질 못 하고 있어요']X = vectorizer.fit_transform(contents_for_vectorize) num_samples, num_features = X.shape num_samples, num_features(4, 20)vectorizer.get_feature_names()['가고', '공원', '그러질', '너무', '놀러', '떠나고', '메리', '바빠서', '바쁜데', '산책', '싫어해요', '싶은데', '싶지만', '어떻하죠', '에서', '여행', '으로', '이상해요', '있어요', '하고']X.toarray().transpose()array([[1, 0, 0, 0], [0, 1, 1, 0], [0, 0, 0, 1], [0, 0, 0, 1], [1, 0, 0, 0], [0, 0, 0, 1], [1, 1, 1, 0], [0, 0, 0, 1], [1, 0, 0, 0], [0, 1, 0, 0], [0, 1, 1, 0], [0, 0, 0, 1], [1, 0, 0, 0], [1, 0, 0, 0], [0, 1, 1, 0], [0, 0, 0, 1], [0, 0, 0, 1], [0, 0, 1, 0], [0, 0, 0, 1], [0, 1, 0, 1]], dtype=int64)new_post = ['메리랑 공원에서 산책하고 놀고 싶어요'] new_post_tokens = [t.morphs(row) for row in new_post] new_post_for_vectorize = [] for content in new_post_tokens: sentence = '' for word in content: sentence = sentence + ' ' + word new_post_for_vectorize.append(sentence) new_post_for_vectorize[' 메리 랑 공원 에서 산책 하고 놀고 싶어요']new_post_vec = vectorizer.transform(new_post_for_vectorize)new_post_vec.toarray()array([[0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1]], dtype=int64)import scipy as sp def dist_raw(v1, v2): delta = v1 - v2 return sp.linalg.norm(delta.toarray())best_doc = None best_dist = 65535 best_i = None for i in range(0, num_samples): post_vec = X.getrow(i) d = dist_raw(post_vec, new_post_vec) print("== Post %i with dist=%.2f : %s" %(i,d,contents[i])) if d<best_dist: best_dist = d best_i = i== Post 0 with dist=3.00 : 메리랑 놀러가고 싶지만 바쁜데 어떻하죠? == Post 1 with dist=1.00 : 메리는 공원에서 산책하고 노는 것을 싫어해요 == Post 2 with dist=2.00 : 메리는 공원에서 노는 것도 싫어해요. 이상해요. == Post 3 with dist=3.46 : 먼 곳으로 여행을 떠나고 싶은데 너무 바빠서 그러질 못하고 있어요print("Best post is %i, dist = %.2f" % (best_i, best_dist)) print('-->', new_post) print('---->', contents[best_i])Best post is 1, dist = 1.00 --> ['메리랑 공원에서 산책하고 놀고 싶어요'] ----> 메리는 공원에서 산책하고 노는 것을 싫어해요for i in range(0,len(contents)): print(X.getrow(i).toarray()) print('---------------------') print(new_post_vec.toarray())[[1 0 0 0 1 0 1 0 1 0 0 0 1 1 0 0 0 0 0 0]] [[0 1 0 0 0 0 1 0 0 1 1 0 0 0 1 0 0 0 0 1]] [[0 1 0 0 0 0 1 0 0 0 1 0 0 0 1 0 0 1 0 0]] [[0 0 1 1 0 1 0 1 0 0 0 1 0 0 0 1 1 0 1 1]] --------------------- [[0 1 0 0 0 0 1 0 0 1 0 0 0 0 1 0 0 0 0 1]]# sp.linalg.norm - https://datascienceschool.net/view-notebook/dd1680bfbaab414a8d54dc978c6e883a/ def dist_norm(v1, v2): v1_normalized = v1 / sp.linalg.norm(v1.toarray()) v2_normalized = v2 / sp.linalg.norm(v2.toarray()) delta = v1_normalized - v2_normalized return sp.linalg.norm(delta.toarray())best_doc = None best_dist = 65535 best_i = None for i in range(0, num_samples): post_vec = X.getrow(i) d = dist_norm(post_vec, new_post_vec) print("== Post %i with dist=%.2f : %s" %(i,d,contents[i])) if d<best_dist: best_dist = d best_i = i== Post 0 with dist=1.28 : 메리랑 놀러가고 싶지만 바쁜데 어떻하죠? == Post 1 with dist=0.42 : 메리는 공원에서 산책하고 노는 것을 싫어해요 == Post 2 with dist=0.89 : 메리는 공원에서 노는 것도 싫어해요. 이상해요. == Post 3 with dist=1.30 : 먼 곳으로 여행을 떠나고 싶은데 너무 바빠서 그러질 못하고 있어요# 결과는 조금 변했으나 유사 문장은 변하지 않음 print("Best post is %i, dist = %.2f" % (best_i, best_dist)) print('-->', new_post) print('---->', contents[best_i])Best post is 1, dist = 0.42 --> ['메리랑 공원에서 산책하고 놀고 싶어요'] ----> 메리는 공원에서 산책하고 노는 것을 싫어해요tf / idf 개념
tf(term frequency) idf(inverse document frequency)
-
텍스트 마이닝에서 사용하는 일종의 단어별로 부과하는 가중치
tf(term frequency)
-
어떤 단어가 문장내에서 자주 등장할 수록 중요도가 높을 것으로 보는 것
idf(inverse document frequency)
-
문서군의 성격에 따라 중요 단어 여부 결정
TF-IDF는 TF와 IDF를 곱한 값을 의미
-
TF-IDF는 모든 문서에서 자주 등장하는 단어는 중요도가 낮다고 판단하며, 특정 문서에서만 자주 등장하는 단어는 중요도가 높다고 판단
-
TF-IDF 값이 낮으면 중요도가 낮은 것이며, TF-IDF 값이 크면 중요도가 큰 것
-
the나 a와 같이 불용어의 경우에는 모든 문서에 자주 등장하기 마련이기 때문에 자연스럽게 불용어의 TF-IDF의 값은 다른 단어의 TF-IDF에 비해서 낮아지게 됨
# tfidf 함수 작성 # idf : log() 문서 n이 너무 커지질 수 있기 때문 def tfidf(t, d, D): tf = float(d.count(t)) / sum(d.count(w) for w in set(d)) idf = sp.log(float(len(D)) / (len([doc for doc in D if t in doc]))) return tf, idfsp.log(3/3)C:\ProgramData\Anaconda3\envs\r_study\lib\site-packages\ipykernel_launcher.py:1: DeprecationWarning: scipy.log is deprecated and will be removed in SciPy 2.0.0, use numpy.lib.scimath.log instead """Entry point for launching an IPython kernel. 0.0sp.log(3/2)C:\ProgramData\Anaconda3\envs\r_study\lib\site-packages\ipykernel_launcher.py:1: DeprecationWarning: scipy.log is deprecated and will be removed in SciPy 2.0.0, use numpy.lib.scimath.log instead """Entry point for launching an IPython kernel. 0.4054651081081644sp.log(3/1)C:\ProgramData\Anaconda3\envs\r_study\lib\site-packages\ipykernel_launcher.py:1: DeprecationWarning: scipy.log is deprecated and will be removed in SciPy 2.0.0, use numpy.lib.scimath.log instead """Entry point for launching an IPython kernel. 1.0986122886681098a, abb, abc = ['a'], ['a','b','b'], ['a','b','c'] D = [a, abb, abc] print(tfidf('a', a, D)) # 'a'는 a에 1/1번 == tf=1, idf == log(3/3) = 0 print(tfidf('b', abb, D)) # 'b'는 abb에 2/3번 == tf=0.666, log(3/2) = 0.4054651081081644 print(tfidf('a', abc, D)) print(tfidf('b', abc, D)) print(tfidf('c', abc, D)) # 'c'는 abc에 1/3번 == tf=0.333, log(3/1) = 1.0986122886681098(1.0, 0.0) (0.6666666666666666, 0.4054651081081644) (0.3333333333333333, 0.0) (0.3333333333333333, 0.4054651081081644) (0.3333333333333333, 1.0986122886681098) C:\ProgramData\Anaconda3\envs\r_study\lib\site-packages\ipykernel_launcher.py:6: DeprecationWarning: scipy.log is deprecated and will be removed in SciPy 2.0.0, use numpy.lib.scimath.log instead# TF-IDF는 TF와 IDF를 곱한 값을 의미 def tfidf(t, d, D): tf = float(d.count(t)) / sum(d.count(w) for w in set(d)) idf = sp.log( float(len(D))/(len([doc for doc in D if t in doc])) ) return tf * idf# scikit-learn 의 TfidfVectorizer import from sklearn.feature_extraction.text import TfidfVectorizer vectorizer = TfidfVectorizer(min_df = 1, decode_error='ignore')contents_tokens = [t.morphs(row) for row in contents] contents_for_vectorize = [] for content in contents_tokens: sentence = '' for word in content: sentence = sentence + ' ' + word contents_for_vectorize.append(sentence) X = vectorizer.fit_transform(contents_for_vectorize) num_samples, num_features = X.shape num_samples, num_features(4, 20)# 말뭉치 확인 vectorizer.get_feature_names()['가고', '공원', '그러질', '너무', '놀러', '떠나고', '메리', '바빠서', '바쁜데', '산책', '싫어해요', '싶은데', '싶지만', '어떻하죠', '에서', '여행', '으로', '이상해요', '있어요', '하고']new_post = ['근처 공원에 메리랑 놀러가고 싶네요.'] new_post_tokens = [t.morphs(row) for row in new_post] new_post_for_vectorize = [] for content in new_post_tokens: sentence = '' for word in content: sentence = sentence + ' ' + word new_post_for_vectorize.append(sentence) new_post_for_vectorize[' 근처 공원 에 메리 랑 놀러 가고 싶네요 .']new_post_vec = vectorizer.transform(new_post_for_vectorize)# 다른 결과를 얻을 수 있음 best_doc = None best_dist = 65535 best_i = None for i in range(0, num_samples): post_vec = X.getrow(i) d = dist_norm(post_vec, new_post_vec) print("== Post %i with dist=%.2f : %s" %(i,d,contents[i])) if d<best_dist: best_dist = d best_i = i print("Best post is %i, dist = %.2f" % (best_i, best_dist)) print('-->', new_post) print('---->', contents[best_i])== Post 0 with dist=0.90 : 메리랑 놀러가고 싶지만 바쁜데 어떻하죠? == Post 1 with dist=1.18 : 메리는 공원에서 산책하고 노는 것을 싫어해요 == Post 2 with dist=1.16 : 메리는 공원에서 노는 것도 싫어해요. 이상해요. == Post 3 with dist=1.41 : 먼 곳으로 여행을 떠나고 싶은데 너무 바빠서 그러질 못하고 있어요 Best post is 0, dist = 0.90 --> ['근처 공원에 메리랑 놀러가고 싶네요.'] ----> 메리랑 놀러가고 싶지만 바쁜데 어떻하죠?'Python' 카테고리의 다른 글
자연어 처리 예제 (0) 2020.07.22 Pandas - pivot_table, Seaborn (0) 2020.07.20 Pandas 기초 (0) 2020.07.16 Numpy 기본 (0) 2020.07.16 OPEN_API를 사용하여 데이터 수집하기 (0) 2020.06.15