-
Machine-Learning머신러닝 2020. 7. 23. 17:19
머신러닝이란?
머신러닝(machine learning) 개요
-
머신러닝이란 인공지능 연구 과제 중 하나
-
인간의 뇌가 학습하는 것처럼 학습의 능력을 컴퓨터로 구현하는 방법
-
샘플 데이터 입력 => 분석 => 특징과 규칙 발견 => 데이터분류 또는 예측
어떻게 특징과 규칙을 찾을까?
-
특징량을 기반으로 구분선 그리기
-
머신러닝 계산을 통해 구분선을 찾아 내는 것
-
많은 경우 거리가 가까우면 비슷한 데이터라고 판정
특징 추출
-
Raw Data => 데이터가 어떤 특징을 가지고 있는 지 확인 => 벡터(vector)
-
벡터란 공간에서 크기와 방향을 가지는 것을 의미
-
어떤 특징을 추출할지가 포인트
회귀 분석 regression analysis
-
Y가 연속된 값일 때 Y = f(x) 모델로 나타 내는 것
-
Y = aX + b 인 경우를 선형 회귀
-
Y: 종복변수(목표변수), X(독립변수,설명변수)
-
X가 1차원 단순회귀, 2차원이상 다중 회귀
머신러닝의 종류
지도학습(교사학습) Supervised learning
-
데이터와 함께 답도 입력
-
다른 데이터의 답 예측
-
답을 특별히 레이블 이라고 함
-
글자를 나타내는 이미지와 답을 학습 => 새로운 이미지의 글자 예측
비지도학습(비교사학습) Unsupervised learning
-
데이터만 입력
-
데이터에서 규칙성을 찾음
-
일반적으로 사람도 알 수없는 본질적은 구조 찾기등에 사용
-
클러스트 분석(Cluster analysis), 주성분 분석(Pricipal component analysis) 등
강화학습 Reinforcement learning
-
부분 적인 답 입력
-
데이터를 기반으로 최적의 답 찾기
-
행동의 주체 <==> 환경(상황, 상태)
-
행동의 주체는 환경을 관찰 => 의사결정(행동) => 보상
-
더 많은 보상을 얻을 수 있는 방향으로 행동을 학습
머신러닝의 흐름
-
데이터 수집 => 가공 => 학습 => 모델 평가 => 정밀도 확인 => 성공
-
학습 => 학습 방법 선택 => 매개변수 조정 => 모델 학습
-
정밀도가 낮으면 매개변수 조정 => 모델 학습 = > 모델 평가 => 정밀도 확인 반복
데이터 수집
-
가장 어려운 부분
-
충분한 양의 데이터 확보 필요
데이터 가공
-
프로그램이 다루기 쉬운 형태로 가공 => 벡터화
-
머신러닝의 어떤 특징을 활용 및 그에 따른 데이터 가공 방법 고민
학습
-
알고리즘 선택 : SVM, 랜덤포레스트, k-menas등
-
데이터와 알고리즘에 맞게 매개변수 지정
평가
-
테스트 데이터를 활용 해 정밀도 확인
머신러닝 응용 분야
클래스 분류(Classification)
-
특정 데이터에 레이블을 붙여 분류
-
스팸 메일 분류, 필기 인식, 증권 사기 등에 사용
클러스터링 - 그룹 나누기(Clustering)
-
값의 유사성 기반으로 데이터를 여러 그룹으로 나누기
-
사용자 취향 별 타겟 광고 제공
추천(Recomendation)
-
특정 데이터를 기반으로 다른 데이터를 추천 하는 것
-
사용자가 인터넷 서점에서 구매한 책을 기반으로 다른 책 추천
회귀(Regression)
-
과거의 데이터를 기반으로 미래의 데이터를 예측 하는 것
-
판매 예측, 주가 변동 등 예측
차원 축소(Dimensionality Reduction)
-
데이터의 특성을 유지하면서 데이터의 양을 줄이는 것
-
양을 줄인다는 것 보다는 고차원을 저차원 데이터로 변환 하는 것
-
데이터를 시각화 하거나 구조를 추출해서 용량을 줄여 계산을 빠르게 하거나 메모리 절약에 사용
-
사람은 얼굴 이미지는 용량이 큰 고차원 데이터 => 이미지에서 눈의 크기, 굴곡, 코의 위치, 입의 위치등을 분석해 숫자로 추출
초과 학습(초과 적합) Overfitting
-
훈련 전용 데이터가 학습돼 있지만 학습되지 않은 데이터에 대해 제대로 된 예측을 못하는 상태
-
데이터가 너무 적은 경우
-
모델에 비해 문제가 너무 복잡한 경우
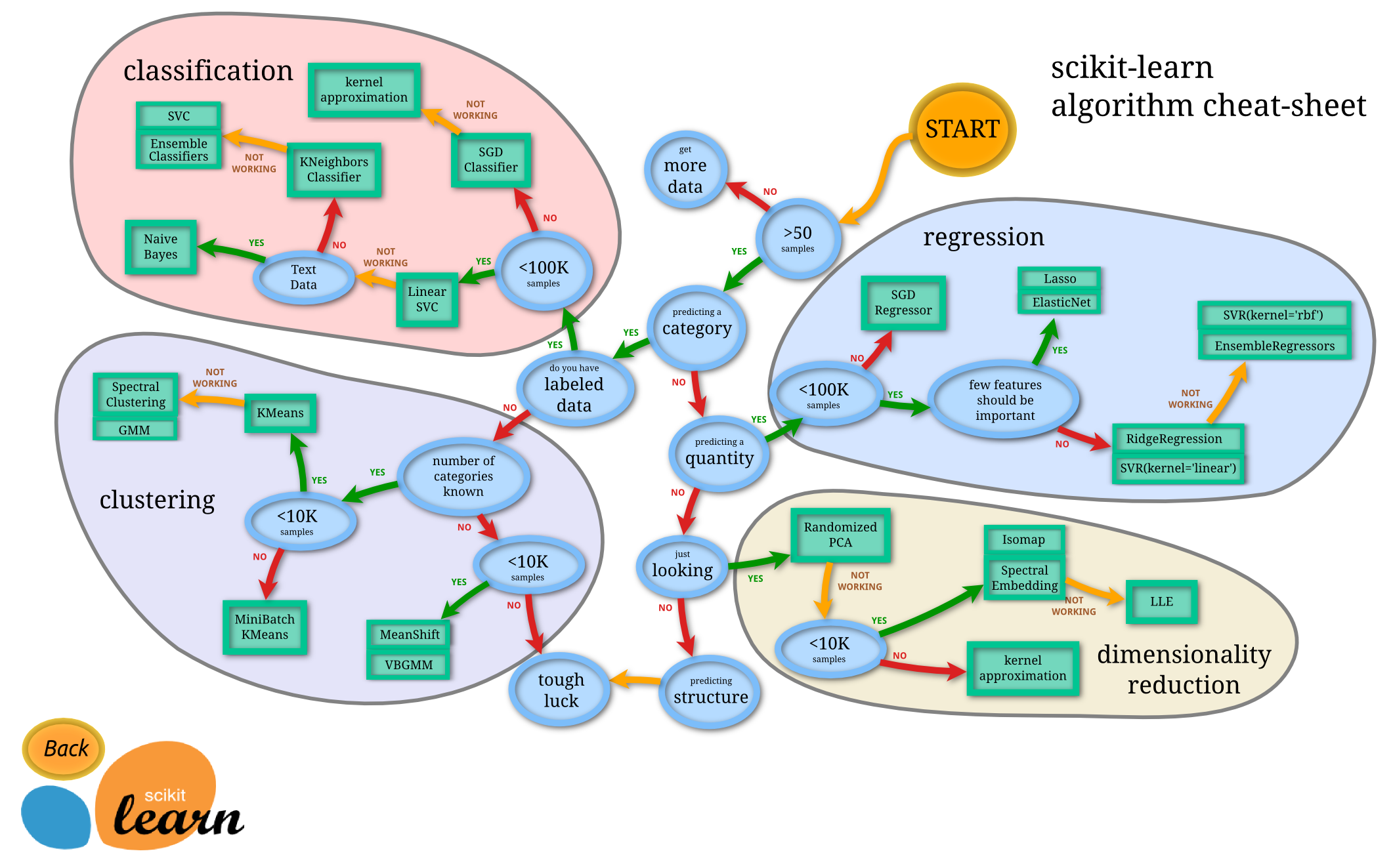
머신러닝 프레임워크 scikit-learn
-
다양한 분류기 지원
-
머신러닝 결과 검증 기능
-
분류, 회귀, 클러스터링, 차원 축소등의 다양한 알고리즘 지원
-
머신러닝 테스트용 샘플 데이터 제공
# !pip install scikit-learn # !pip install scipyXOR 연산 학습하기
from sklearn import svm# XOR의 계산 결과 데이터 --- (1) xor_data = [ #P, Q, result [0, 0, 0], [0, 1, 1], [1, 0, 1], [1, 1, 0] ] # 학습을 위해 데이터와 레이블 분리하기 --- (2) # 학습시키기 fit() 매개변수에 필요 data = [] # 훈련데이터 / 테스트데이터 label = [] # 답 for row in xor_data: p = row[0] q = row[1] r = row[2] data.append([p, q]) label.append(r) # 데이터 학습시키기 fit() --- (3) # SVC 알고리즘 사용 clf = svm.SVC() clf.fit(data, label) # 데이터 예측하기 predict() --- (4) pre = clf.predict(data) print('예측 결과 :', pre) # 결과 확인하기 --- (5) ok = 0; total = 0 for idx, answer in enumerate(label): p = pre[idx] if p == answer: ok += 1 total += 1 print("정답률:", ok, "/", total, "=", ok/total)예측 결과 : [0 1 1 0] 정답률: 4 / 4 = 1.0data[[0, 0], [0, 1], [1, 0], [1, 1]]label[0, 1, 1, 0]prearray([0, 1, 1, 0])프레임워크로 작성하기
-
판다스로 데이터와 레이블 나누기
-
scikit-learn 정답률 계산 기능 등 내장
import pandas as pd from sklearn import svm, metrics# XOR 연산 xor_input = [ [0, 0, 0], [0, 1, 1], [1, 0, 1], [1, 1, 0] ] # 입력을 학습 전용 데이터와 테스트 전용 데이터로 분류하기 --- (1) xor_df = pd.DataFrame(xor_input) xor_data = xor_df.loc[:,0:1] # 데이터 xor_label = xor_df.loc[:,2] # 레이블 # 데이터 학습과 예측하기 -- (2) clf = svm.SVC() clf.fit(xor_data, xor_label) # 훈련, 학습, 모델만들기 같은말임 pre = clf.predict(xor_data) # 정답률 구하기 --- (3) ac_score = metrics.accuracy_score(xor_label, pre) print('정답률 =', ac_score)정답률 = 1.0xor_label0 0 1 1 2 1 3 0 Name: 2, dtype: int64prearray([0, 1, 1, 0], dtype=int64)붓꽃의 품종 분류하기
-
외떡잎식물 백합목 붓꽃과의 여러해살이풀 '붓꽃' 분류
-
머신러닝을 사용해 꽃입과 꽃받치의 크기 기반 분류
붓꽃 데이터 구하기
-
https://wikibook.co.kr/pyml-rev/ 예제코드 다운로드
-
Fisher의 붓꽃 데이터 internet에 공개되 있음
-
iris.csv 검색 (ch4)
-
판다스의 데이터로도 포함되 있음
데이터 설명
-
붓꽃 종류 3가지 Iris-setosa, Iris-versicolor, Iris-virginica
-
SepalLength : 꽃받침의 길이
-
SepalWidth : 꽃받침의 폭
-
PetalLength : 꽃잎의 길이
-
PetalWidth : 꽃잎의 너비
머신러닝으로 붓꽃 품종 분류하기
-
150개의 데이터 / 100개 훈련용 / 50개 테스트용
from sklearn import svm, metrics import random, re# 붓꽃의 CSV 데이터 읽어 들이기 --- (1) csv = [] with open('pyml_rev_examples/ch4/iris.csv', 'r', encoding='utf-8') as fp: # 한 줄씩 읽어 들이기 for line in fp: line = line.strip() # 줄바꿈 제거 cols = line.split(',') # 쉼표로 자르기 # 문자열 데이터를 숫자로 변환하기 fn = lambda n : float(n) if re.match(r'^[0-9\.]+$', n) else n cols = list(map(fn, cols)) csv.append(cols) # 가장 앞 줄의 헤더 제거 del csv[0]csv[:3][[5.1, 3.5, 1.4, 0.2, 'Iris-setosa'], [4.9, 3.0, 1.4, 0.2, 'Iris-setosa'], [4.7, 3.2, 1.3, 0.2, 'Iris-setosa']]data = pd.read_csv('pyml_rev_examples/ch4/iris.csv') data.head()SepalLength SepalWidth PetalLength PetalWidth Name 0 5.1 3.5 1.4 0.2 Iris-setosa 1 4.9 3.0 1.4 0.2 Iris-setosa 2 4.7 3.2 1.3 0.2 Iris-setosa 3 4.6 3.1 1.5 0.2 Iris-setosa 4 5.0 3.6 1.4 0.2 Iris-setosa # 데이터 셔플하기(섞기) -- (2) random.shuffle(csv)# 학습 전용 데이터와 테스트 전용 데이터 분할하기(2:1 비율) --- (3) total_len = len(csv) train_len = int(total_len * 2 / 3) train_data = [] train_label = [] test_data = [] test_label = [] for i in range(total_len): data = csv[i][0:4] label = csv[i][4] if i < train_len: train_data.append(data) train_label.append(label) else: test_data.append(data) test_label.append(label)train_data[:3][[4.4, 3.0, 1.3, 0.2], [5.2, 3.5, 1.5, 0.2], [5.8, 2.7, 3.9, 1.2]]train_label[:3]['Iris-setosa', 'Iris-setosa', 'Iris-versicolor']test_data[:3][[5.7, 2.9, 4.2, 1.3], [6.4, 3.2, 5.3, 2.3], [6.3, 2.7, 4.9, 1.8]]test_label[:3]['Iris-versicolor', 'Iris-virginica', 'Iris-virginica']# 데이터를 학습시키고 예측하기 --- (4) clf = svm.SVC() clf.fit(train_data, train_label) pre = clf.predict(test_data)# 정답률 구하기 --- (5) ac_score = metrics.accuracy_score(test_label, pre) print('정답률 =', ac_score)정답률 = 0.86훈련용 / 테스트 데이터 분할 메서드
-
model_selection 모듈의 train_test_split()
import pandas as pd from sklearn import svm, metrics from sklearn.model_selection import train_test_split# 붓꽃의 CSV 데이터 읽어 들이기 --- (※1) csv = pd.read_csv('pyml_rev_examples/ch4/iris.csv')# 필요한 열 추출하기 --- (2) csv_data = csv[["SepalLength","SepalWidth","PetalLength","PetalWidth"]] csv_label = csv['Name']# 학습 전용 데이터와 테스트 전용 데이터로 나누기 --- (3) train_data, test_data, train_label, test_label = train_test_split(csv_data, csv_label)train_data[:3] len(train_data)112test_data[:3] len(test_data)38train_label[:3]23 Iris-setosa 51 Iris-versicolor 122 Iris-virginica Name: Name, dtype: objecttest_label[:3]54 Iris-versicolor 35 Iris-setosa 15 Iris-setosa Name: Name, dtype: object# 데이터 학습시키고 예측하기 --- (4) clf = svm.SVC() clf.fit(train_data, train_label) pre = clf.predict(test_data)# 정답률 구하기 --- (5) ac_score = metrics.accuracy_score(test_label, pre) print('정답률 = ', ac_score)정답률 = 0.9736842105263158이미지 내부의 문자 인식
손글씨 숫자 인식
데이터 수집 MNIST : THE MINIST DATABASE
-
THE MINIST DATABASE of handwritten digits
-
학습전용 6만개 / 테스트 전용 1만개
-
MNIST 자체 데이터베이스 형식
-
train-images-idx3-ubyte.gz: training set images (9912422 bytes)
-
train-labels-idx1-ubyte.gz: training set labels (28881 bytes)
-
t10k-images-idx3-ubyte.gz: test set images (1648877 bytes)
-
t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes)
데이터 구조
-
사이트 확인: FILE FORMATS FOR THE MNIST DATABASE
-
이미지데이터는 각 픽셀을 그레이스케일 256단계
-
왼쪽 위부터 오른쪽 아래로 차례차례 픽셀이 나열된 형태
-
0:흰색, 1~255 숫자가 클수록 짙은 부분
-
바이너리 데이터 => CSV로 변환
-
<레이블>, <28x28의 픽셀 데이터>
-
각파일은 32bit(매빅넘버)+32bit(이미지갯수)+이미지(8byte씩)
데이터 변환
# binary 파일 변환위한 모듈 import structdef to_csv(name, maxdata): # 레이블 파일과 이미지 열기 lbl_f = open("mnist/"+name+"-labels.idx1-ubyte", "rb") img_f = open("mnist/"+name+"-images.idx3-ubyte", "rb") csv_f = open("mnist/"+name+".csv", "w", encoding="utf-8") # 헤더 정보 읽기 --- (1) # unpack() 원하는 바이너리수 많큼 읽고 정수로 변환 # > 리틀 엔디안 II 4byte4byter # https://suspected.tistory.com/155 # PGM : 글자파일로 이미지 생성 가능 mag, lbl_count = struct.unpack(">II", lbl_f.read(8)) mag, img_count = struct.unpack(">II", img_f.read(8)) rows, cols = struct.unpack(">II", img_f.read(8)) pixels = rows * cols # 이미지 데이터를 읽고 CSV로 저장하기 --- (2) res = [] for idx in range(lbl_count): if idx > maxdata : break label = struct.unpack("B", lbl_f.read(1))[0] bdata = img_f.read(pixels) sdata = list(map(lambda n: str(n), bdata)) csv_f.write(str(label)+",") csv_f.write(",".join(sdata)+"\r\n") # 잘 저장됐는지 이미지 파일로 저장해서 테스트 하기 --- (3) if idx < 10: s = "P2 28 28 255\n" s += " ".join(sdata) iname = "./mnist/{0}-{1}-{2}.pgm".format(name, idx, label) with open(iname, "w", encoding="utf-8") as f: f.write(s) csv_f.close() lbl_f.close() img_f.close()# 결과를 파일로 출력하기 --- (4) # 6만개 처리 시간이 많이 걸려 학습 1000개 / 테스트 500개 to_csv('train', 1000) to_csv('t10k', 500)pgm view
-
value view: http://paulcuth.me.uk/netpbm-viewer/
-
image view: https://www.xnview.com/
-
image make: https://oneday0012.tistory.com/8
이미지 데이터 학습하기
-
손글씨 숫자 데이터를 벡터로 변환
from sklearn import model_selection, svm, metrics# CSV 파일을 읽어 들이고 가공하기 --- (1) def load_csv(fname): labels = [] images = [] with open(fname, 'r') as f: for line in f: cols = line.split(',') if len(cols) < 2 :continue labels.append(int(cols.pop(0))) # 0<= vals < 1 vals = list(map(lambda n: int(n) / 256, cols)) images.append(vals) return {'labels':labels, 'images':images} data = load_csv('./mnist/train.csv') test = load_csv('./mnist/t10k.csv')# 학습하기 --- (2) clf = svm.SVC() clf.fit(data['images'], data['labels'])SVC()# 예측하기 --- (3) predict = clf.predict(test['images'])# 결과 확인하기 --- (4) ac_score = metrics.accuracy_score(test['labels'], predict) cl_report = metrics.classification_report(test["labels"], predict) print("정답률 =", ac_score) print("리포트 =") print(cl_report)정답률 = 0.8842315369261478 리포트 = precision recall f1-score support 0 0.87 0.98 0.92 42 1 0.99 1.00 0.99 67 2 0.91 0.89 0.90 55 3 0.94 0.72 0.81 46 4 0.86 0.93 0.89 55 5 0.75 0.82 0.78 50 6 0.95 0.81 0.88 43 7 0.79 0.94 0.86 49 8 0.94 0.82 0.88 40 9 0.89 0.87 0.88 54 accuracy 0.88 501 macro avg 0.89 0.88 0.88 501 weighted avg 0.89 0.88 0.88 501외국어 문장 판별하기
-
외국어 글자를 읽어 들이고 어떤 언어인지 판정하는 프로그램 만들기
-
알파벳을 사용하는 언어라도 프랑스어, 타갈로어(필리핀), 인도네시아어 등
판정 방법
-
글자를 곧바로 학습기에 넣을 수 없음
-
글자를 나타내는 백터로 변경
-
언어가 다르면 알파벳 출현 빈도가 다름(언어학)
-
a 부터 z 까지의 출현 빈도를 확인해서 이를 특징으로 사용
샘플 데이터 수집
-
각 언여별로 풍부한 데이터가 있는 위키피디아 글자 사용
-
영어(en), 프랑스어(fr), 인도네시아(id), 타갈로어(tl) 테스트
-
학습데이터 20개 / 테스트 8개
언어 판별
from sklearn import svm, metrics import glob, os.path, re, json# 텍스트를 읽어 들이고 출현 빈도 조사하기 --- (※1) def check_freq(fname): name = os.path.basename(fname) # 파일이름 앞의 두 문자가 언어 코드 lang = re.match(r'^[a-z]{2,}', name).group() # print(name) # print(lang) with open(fname, 'r', encoding='utf-8') as f: text = f.read() text = text.lower() # 소문자 변환 # 숫자 세기 변수(cnt) 초기화 하기 cnt = [0 for n in range(0, 26)] # ord() 함수 : 특정한 한 문자를 아스키 코드 값으로 변환해 주는 함수 code_a = ord('a') # 97 code_z = ord('z') # 122 # print(code_a) # 알파벳 출현 횟수 구하기 --- (2) for ch in text: n = ord(ch) # print(n) if code_a <= n <= code_z: # a~z 사이에 있을 때, 알파벳만 처리 cnt[n - code_a] += 1 # 정규화 하기 --- (3) 하는 이유 : 각 텍스트 파일에 글자수가 다르므로 total = sum(cnt) freq = list(map(lambda n: n / total, cnt)) return (freq, lang)# 각 파일 처리하기 def load_files(path): freqs = [] labels = [] # glob - 특정 파일만 출력하기 # https://wikidocs.net/3746 file_list = glob.glob(path) for fname in file_list: r = check_freq(fname) freqs.append(r[0]) # 빈도수 labels.append(r[1]) # 국가명 return {'freqs':freqs, 'labels':labels} data = load_files("pyml_rev_examples/ch4/lang/train/*.txt") test = load_files("pyml_rev_examples/ch4/lang/test/*.txt")# 이후를 대비해서 JSON으로 결과 저장하기 - 이미지 출력용 # JSON 으로 결과 저장했지만 피클로 저장해도 상관없음 with open('pyml_rev_examples/ch4/lang/freq.json', 'w', encoding='utf-8') as fp: json.dump([data, test], fp)# 학습하기 --- (4) clf = svm.SVC() clf.fit(data["freqs"], data["labels"])SVC()# 예측하기 --- (5) predict = clf.predict(test['freqs'])# 결과 테스트하기 --- (6) ac_score = metrics.accuracy_score(test['labels'], predict) cl_report = metrics.classification_report(test['labels'], predict) print("정답률 =", ac_score) print("리포트 =") print(cl_report)정답률 = 1.0 리포트 = precision recall f1-score support en 1.00 1.00 1.00 2 fr 1.00 1.00 1.00 2 id 1.00 1.00 1.00 2 tl 1.00 1.00 1.00 2 accuracy 1.00 8 macro avg 1.00 1.00 1.00 8 weighted avg 1.00 1.00 1.00 8데이터마다의 분포를 그래프로 확인
-
알파벳의 빈도가 어떻게 다른지 시각적으로 확인
import matplotlib.pyplot as plt import pandas as pd import json# 알파벳 출현 빈도 데이터 읽어 들이기 --- (※1) with open("pyml_rev_examples/ch4/lang/freq.json", "r", encoding="utf-8") as fp: freq = json.load(fp)# 언어마다 계산하기 --- (2) lang_dic = {} for i, lbl in enumerate(freq[0]['labels']): fq = freq[0]['freqs'][i] if not (lbl in lang_dic): lang_dic[lbl] = fq continue for idx, v in enumerate(fq): lang_dic[lbl][idx] = (lang_dic[lbl][idx] + v) / 2# Pandas의 DataFrame에 데이터 넣기 --- (3) asclist = [[chr(n) for n in range(97, 97+26)]] df = pd.DataFrame(lang_dic, index=asclist)df.head()en fr id tl a 0.073919 0.076504 0.171599 0.201979 b 0.020681 0.012910 0.025640 0.022360 c 0.033506 0.036590 0.007429 0.015670 d 0.039112 0.050464 0.040608 0.027269 e 0.131043 0.148523 0.081552 0.055009 # 그래프 그리기 --- (4) df.plot(kind='bar', subplots=True, ylim=(0, 0.15)) # subplots=True =>각각 plt.savefig('lang-plot.png')
# 다른 그래프로 확인 df.plot(kind='line')
Web 인터페이스 추가
-
언어판정 모델을 활용해서 언어 판정 웹 서비스 개발
!pip install joblibRequirement already satisfied: joblib in c:\programdata\anaconda3\envs\r_study\lib\site-packages (0.16.0)# 언어 판정 마다 데이터 학습은 필요 없으니 학습 모델 저장 from sklearn import svm import joblib# 각 언어의 출현 빈도 데이터(JSON) 읽어 들이기 with open("pyml_rev_examples/ch4/lang/freq.json", "r", encoding="utf-8") as fp: d = json.load(fp) data = d[0] # 데이터 학습하기 clf = svm.SVC() clf.fit(data['freqs'], data['labels']) # 학습 데이터 저장하기 # 학습한 모델을 저장할 수 있는 joblib # https://minwook-shin.github.io/python-disk-caching-parallel-computing-using-joblib/ joblib.dump(clf, 'pyml_rev_examples/ch4/lang/freq.pkl') print('ok')okcgi program 구성
-
파이썬 내장 웹서버 구성
-
cgi-bin 폴더 내부에 프로그램 배치, 폴더 상위가 root 가 됨
-
root/cgi-bin/웹프로그램.py
-
root 에서 명령어 실행(anaconda 콘솔에서 실행)
-
python -m http.server --cgi 포트
-
-
웹프로그램 실행
#!/usr/bin/env python3 import cgi, os.path from sklearn.externals import joblib # 학습 데이터 읽어 들이기 ★ pklfile = os.path.dirname(__file__) + '/freq.pkl' clf = joblib.load(pklfile) # 텍스트 입력 양식 출력하기 def show_form(text, msg=""): print("Content-Type: text/html; charset=utf-8") print("") print(""" <html><body><form> <textarea name="text" rows="8" cols="40">{0}</textarea> <p><input type="submit" value="판정"></p> <p>{1}</p> </form></body></html> """.format(cgi.escape(text), msg)) # 판정하기 def detect_lang(text): # 알파벳 출현 빈도 구하기 text = text.lower() code_a, code_z = (ord("a"), ord("z")) cnt = [0 for i in range(26)] for ch in text: n = ord(ch) - code_a if 0 <= n < 26: cnt[n] += 1 total = sum(cnt) if total == 0: return "입력이 없습니다" freq = list(map(lambda n: n/total, cnt)) # 언어 예측하기 ★ res = clf.predict([freq]) # 언어 코드를 한국어로 변환하기 lang_dic = {"en":"영어","fr":"프랑스어", "id":"인도네시아어", "tl":"타갈로그어"} return lang_dic[res[0]] # 입력 양식의 값 읽어 들이기 form = cgi.FieldStorage() text = form.getvalue("text", default="") msg = "" if text != "": lang = detect_lang(text) msg = "판정 결과:" + lang # 입력 양식 출력 show_form(text, msg)-
위 코드 메모장에 붙여넣기 후 lang-Webapp.py (파일형식 : 모든파일)로 저장
-