-
랜덤 포레스트 - Random Forest
-
집단 학습을 기반으로 고정밀 분류, 회귀, 클러스트링 구현
-
학습 데이터로 다수의 의사결정 트리를 만들고 그 결과의 다수결로 결과 유도로 높은 정밀도
-
무작위 샘플링과 다수의 의사결정 트리 => Random Forest
결정 트리(Decision Tree)
-
분류(Classification)와 회귀(Regression) 모두 가능한 지도 학습 모델 중 하나
-
결정 트리는 스무고개 하듯이 예/아니오 질문을 이어가며 학습
-
한번의 분기 때마다 변수 영역을 두 개로 구분
매, 펭귄, 돌고래, 곰을 구분한다고 생각해봅시다


-
Terminal Node는 LeafNode 라고도 함
프로세스
먼저 데이터를 가장 잘 구분할 수 있는 질문을 기준으로 나누기
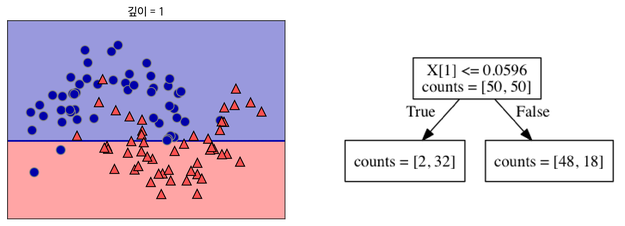
나뉜 각 범주에서 또 다시 데이터를 가장 잘 구분할 수 있는 질문을 기준으로 나눔

이를 지나치게 많이 하면 아래와 같이 오버피팅
-
결정 트리에 아무 파라미터를 주지 않고 모델링하면 오버피팅
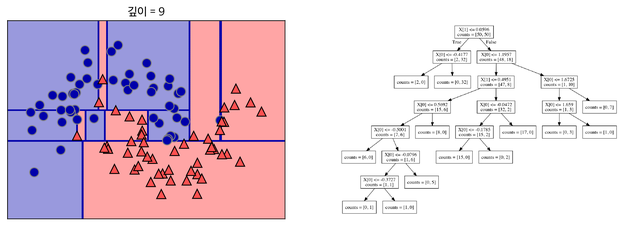
가지치기(Pruning) - 오버피팅 막기 전략
-
트리에 가지가 너무 많으면 오버피팅
-
한 노드가 분할하기 위한 최소 데이터수를 제한 min_sample_split = 10
-
max_depth를 통해서 최대 깊이를 지정max_depth = 4이면, 깊이가 4보다 크게 가지를 치지 않음
알고리즘: 엔트로피(Entropy), 불순도(Impurity)

불순도(Impurity)
-
해당 범주 안에 서로 다른 데이터가 얼마나 섞여 있는지를 뜻함
-
한 범주에 하나의 데이터만 있다면 불순도가 최소(혹은 순도가 최대)
-
한 범주 안에 서로 다른 두 데이터가 정확히 반반 있다면 불순도가 최대(혹은 순도가 최소)
-
결정 트리는 불순도를 최소화(혹은 순도를 최대화)하는 방향으로 학습을 진행
엔트로피(Entropy)
-
불순도(Impurity)를 수치적으로 나타낸 척도
-
엔트로피가 높다는 것은 불순도도 높다는 뜻
-
엔트로피가 1이면 불순도가 최대
-
한 범주 안에 데이터가 정확히 반반 있다는 뜻
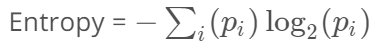
엔트로피 공식 (Pi = 범주 i에 속한 데이터의 비율)
엔트로피 예제
-
경사, 표면, 속도 제한을 기준으로 속도가 느린지 빠른지 분류해놓은 표
-
X 가 경사, 표면, 속도 제한
-
Y 가 속도(라벨)
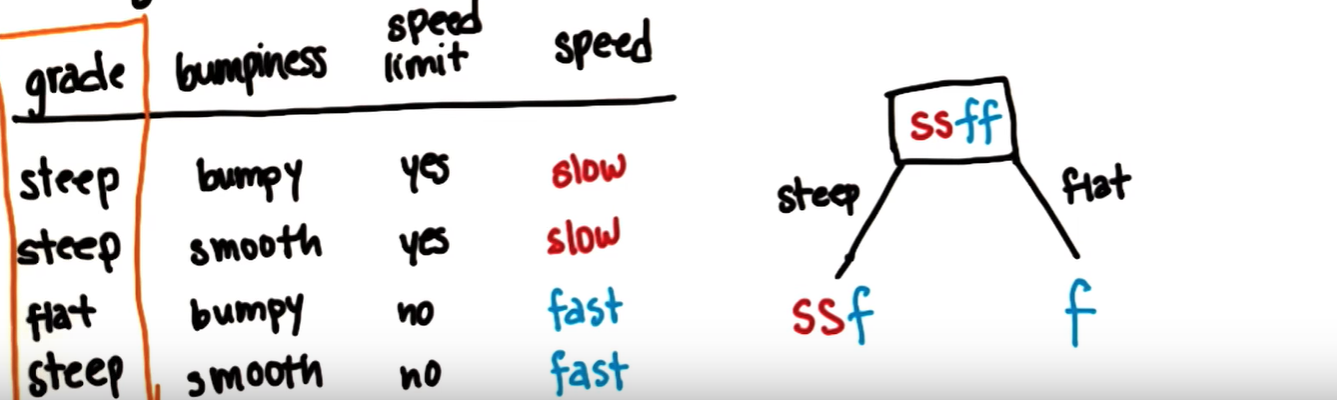
경사 표면 속도 제한 속도 steep bumpy yes slow steep smooth yes slow flat bumpy no fast steep smooth no fast -
속도 라벨에는 slow, slow, fast, fast로 총 4개의 examples
-
Pi는 범주 i에 속한 데이터의 비율
-
i를 slow라고 했을 때, P_slow = 0.5 (2/4)
-
P_fast도 0.5 (ff/ssff)
-
전체 엔트로피 : 0.5 + 0.5 = 1
# 전체 엔트로피 공식으로 계산 import math P_slow = 0.5 P_fast = 0.5 Entropy = - P_slow * math.log(P_slow, 2) - P_fast * math.log(P_fast, 2) Entropy1.0정보 획득 (Information gain)
-
엔트로피가 1인 상태에서 0.7인 상태로 바뀌었다면 정보 획득(information gain)은 0.3
-
분기 이전의 엔트로피에서 분기 이후의 엔트로피를 뺀 수치가 바로 정보 획득량
-
결정 트리 알고리즘은 information gain을 최대화하는 방향으로 학습이 진행
-
Information gain = entropy(parent) - [weighted average] entropy(children)
경사를 기준으로 첫 분기
{steep:['slow','slow','fast'],flat:'fast' }
- flat: 엔트로피 0 entropy(parent) = 1 entropy(flat) = 0 entropy(steep) = P_slow * log2(P_slow) - P_fast * log2(P_fast) entropy(steep) = - (2/3) * log2(2/3) - (1/3) * log2(1/3) entropy(steep) = 0.9184 [weighted average] entropy(children) = weighted average of steep * entropy(steep) + weighted average of flat * entropy(flat) entropy(children) = 3/4 * (0.9184) + 1/4 * (0) entropy(children) = 0.6888 information gain = entropy(parent) - [weighted average] entropy(children) information gain = 1 - 0.6888 = 0.3112-
표면 기준 분기, 속도제한 기준 분기의 information gain 을 비교
-
가장 정보 획득이 많은 방향으로 학습 진행
랜덤 포레스트(Random Forest)
-
결정 트리 하나만으로도 머신러닝 가능
-
결정 트리의 단점은 훈련 데이터에 오버피팅이 되는 경향이 큼
-
여러 개의 결정 트리를 통해 랜덤 포레스트를 만들면 오버피팅 되는 단점을 해결
원리
건강의 위험도를 예측
-
건강의 위험도를 예측하기 위해서는 많은 요소를 고려
-
성별, 키, 몸무게, 지역, 운동량, 흡연유무, 음주 여부, 혈당, 근육량, 기초 대사량 등등등... 수많은 요소가 필요
-
Feature가 30개라 했을 때 30개의 Feature를 기반으로 하나의 결정 트리를 만든다면 트리의 가지가 많아질 것이고, 이는 오버피팅의 결과를 야기
-
30개의 Feature 중 랜덤으로 5개의 Feature만 선택해서 하나의 결정 트리 생성
-
계속 반복하여 여러 개의 결정 트리 생성
-
여러 결정 트리들이 내린 예측 값들 중 가장 많이 나온 값을 최종 예측값으로 지정
-
이렇게 의견을 통합하거나 여러 가지 결과를 합치는 방식을 앙상블(Ensemble)이라고 함
-
하나의 거대한 (깊이가 깊은) 결정 트리를 만드는 것이 아니라 여러 개의 작은 결정 트리를 만드는 것
-
분류 : 여러 개의 작은 결정 트리가 예측한 값들 중 가장 많은 값
-
회귀 : 평균값
파라미터
-
n_estimators: 랜덤 포레스트 안의 결정 트리 갯수
-
n_estimators는 클수록 좋지만 그만큼 메모리와 훈련 시간이 증가
-
max_features: 무작위로 선택할 Feature의 개수, 일반적으로 Default
랜덤 포레스트 example
DataSet
-
UCI 머신러닝 레포지토리에 공개된 독버섯 관련된 데이터
-
8,124종류의 버섯의 특징과 독이 있는지 적혀있는 데이터 세트
p,x,s,n,t,p,f,c,n,k,e,e,s,s,w,w,p,w,o,p,k,s,u e,x,s,y,t,a,f,c,b,k,e,c,s,s,w,w,p,w,o,p,n,n,g e,b,s,w,t,l,f,c,b,n,e,c,s,s,w,w,p,w,o,p,n,n,m p,x,y,w,t,p,f,c,n,n,e,e,s,s,w,w,p,w,o,p,k,s,u e,x,s,g,f,n,f,w,b,k,t,e,s,s,w,w,p,w,o,e,n,a,g e,x,y,y,t,a,f,c,b,n,e,c,s,s,w,w,p,w,o,p,k,n,g-
한 줄이 버섯 한 종류
-
첫 번째 열 독 유무 p:poisionous, e:edible
-
두 번째 열 버섯 머리 모양 b:벨, c:원뿔, x:볼록, f:평평, k:혹, s:오목
-
네 버째 열 버섯의 머리 색 n:갈색, b:황갈색, c:연한갈색, g:회색, r:녹색, p:분홍색, u:보라색, e:붉은색, w:흰색, y:노란색
-
나머지는 필요시 UCI 사이트에서 확인
머신러닝 할때는 이런 문자를 어떻게 숫자로 변환하는 지가 문제
-
각각의 기호가 한 글자 => 문자코드로 변환 활용
import pandas as pd from sklearn.ensemble import RandomForestClassifier from sklearn import metrics from sklearn.model_selection import train_test_split# 데이터 읽어 들이기--- (※1) mr = pd.read_csv("data/mushroom.csv", header=None) mr.head(3)0 1 2 3 4 5 6 7 8 9 ... 13 14 15 16 17 18 19 20 21 22 0 p x s n t p f c n k ... s w w p w o p k s u 1 e x s y t a f c b k ... s w w p w o p n n g 2 e b s w t l f c b n ... s w w p w o p n n m 3 rows × 23 columns
# 데이터 내부의 기호를 숫자로 변환하기--- (※2) label = [] data = [] attr_list = [] for row_index, row in mr.iterrows(): # 라벨(독여부) 생성 label.append(row.loc[0]) row_data = [] # 나머지를 데이터로 for v in row.loc[1:]: # ord() 특정한 한 문자를 아스키 코드 값으로 변환 row_data.append(ord(v)) data.append(row_data)data[:1][[120, 115, 110, 116, 112, 102, 99, 110, 107, 101, 101, 115, 115, 119, 119, 112, 119, 111, 112, 107, 115, 117]]# 학습 전용과 테스트 전용 데이터로 나누기 --- (※3) data_train, data_test, label_train, label_test = \ train_test_split(data, label)# 데이터 학습시키기 --- (※4) clf = RandomForestClassifier() clf.fit(data_train, label_train)RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None, criterion='gini', max_depth=None, max_features='auto', max_leaf_nodes=None, max_samples=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=None, oob_score=False, random_state=None, verbose=0, warm_start=False)# 데이터 예측하기 --- (※5) predict = clf.predict(data_test) predictarray(['e', 'p', 'e', ..., 'p', 'p', 'p'], dtype='<U1')# 결과 테스트하기 --- (※6) ac_score = metrics.accuracy_score(label_test, predict) cl_report = metrics.classification_report(label_test, predict) print("정답률 =", ac_score) print("리포트 =\n", cl_report) 정답률 = 1.0 리포트 = precision recall f1-score support e 1.00 1.00 1.00 1045 p 1.00 1.00 1.00 986 accuracy 1.00 2031 macro avg 1.00 1.00 1.00 2031 weighted avg 1.00 1.00 1.00 2031데이터를 숫자로 변경할 때 주의할 사항
-
빨강:1, 파랑:2, 초록:3, 흰색:4 할당
-
이때 숫자가 연속돼 있다면 파랑은 2배가 흰색
-
빨강과 파랑은 값이 가까움
-
순서대로 할당이라면 연속이 아니고 분류변수 아래와 같이 할당
-
빨강 = 1 0 0 0
-
파랑 = 0 1 0 0
-
초록 = 0 0 1 0
-
흰색 = 0 0 0 1
버섯 데이터 분류변수로 할당
test_dict = {'dic': {}, 'cnt':0} test_dict['dic']['x']=0 test_dict['dic'] test_dict['dic']['y']=0 test_dict['dic']{'x': 0, 'y': 0}# 데이터 내부의 분류 변수 전개하기 label = [] data = [] attr_list = [] for row_index, row in mr.iterrows(): #print(row_index) label.append(row.loc[0]) exdata = [] for col, v in enumerate(row.loc[1:]): if row_index == 0: attr = {"dic": {}, "cnt":0} attr_list.append(attr) #print(attr) else: attr = attr_list[col] #print(attr) # 버섯의 특징 기호를 배열로 나타내기 12 #9. gill-color: black=k,brown=n,buff=b,chocolate=h,gray=g, green=r,orange=o,pink=p,purple=u,red=e, white=w,yellow=y d = [0,0,0,0,0,0,0,0,0,0,0,0] if v in attr["dic"]: idx = attr["dic"][v] else: idx = attr["cnt"] attr["dic"][v] = idx attr["cnt"] += 1 #print(attr) d[idx] = 1 #print(d) exdata += d #print(exdata) data.append(exdata)mr.head(3)0 1 2 3 4 5 6 7 8 9 ... 13 14 15 16 17 18 19 20 21 22 0 p x s n t p f c n k ... s w w p w o p k s u 1 e x s y t a f c b k ... s w w p w o p n n g 2 e b s w t l f c b n ... s w w p w o p n n m 3 rows × 23 columns
# 학습 전용 데이터와 테스트 전용 데이터로 나누기 data_train, data_test, label_train, label_test = \ train_test_split(data, label) # 데이터 학습시키기 clf = RandomForestClassifier() clf.fit(data_train, label_train) # 데이터 예측하기 predict = clf.predict(data_test) # 결과 테스트하기 ac_score = metrics.accuracy_score(label_test, predict) print("정답률 =", ac_score) 정답률 = 1.0결정트리 참고
독버섯 판별 R로 작성 참고
'머신러닝' 카테고리의 다른 글
교차검증 (0) 2020.07.28 SVM (0) 2020.07.28 데이터 전처리 (0) 2020.07.23 Machine-Learning (0) 2020.07.23 -